OpenClaw 源代码全链路解析:一条消息背后的十层旅程
当你向 OpenClaw 发出一句"你好",从按下发送键到看见回复,背后到底经历了什么?本文基于 OpenClaw 源码,逐层拆解其完整执行链路。
引言
OpenClaw 是近期 AI 领域最受关注的开源项目之一。很多人以为它的核心是那个聊天框,但本质上,它首先是一个本地优先(Local-First)的网关平台。只有先把网关跑起来,建立统一的会话管理、渠道管理、工具管理和事件分发能力,来自不同渠道的消息才能汇总进来,进入后续的处理流程。
下面,我们就来一层层拆开这套系统,看看一条用户消息是如何被处理的。
第一层:网关启动 - 以 WhatsApp 渠道为例
源文件:extensions/whatsapp/src/auto-reply/monitor.ts
核心函数:monitorWebChannel
整个流程的起点和大模型没有任何关系,而是从网关的启动开始。
启动过程分为以下几步:
- 检查网络连接
- 加载
openclaw.json总配置文件,其中包含智能体、渠道、环境变量、鉴权信息、模型配置等所有核心字段 - 解析当前账号(如 WhatsApp 账号)
- 进入持续循环:创建消息处理器(createWebOnMessageHandler)、启动渠道监听器(listener)、设置心跳机制(heartbeat)和看门狗定时器(watchdogTimer)、处理连接断开与重连、持续更新系统运行状态
只有这整套流程全部完成,网关成功启动,OpenClaw 才算正式进入就绪状态,随时准备接收用户消息。没有网关的支撑,后面所有的能力都无从谈起。
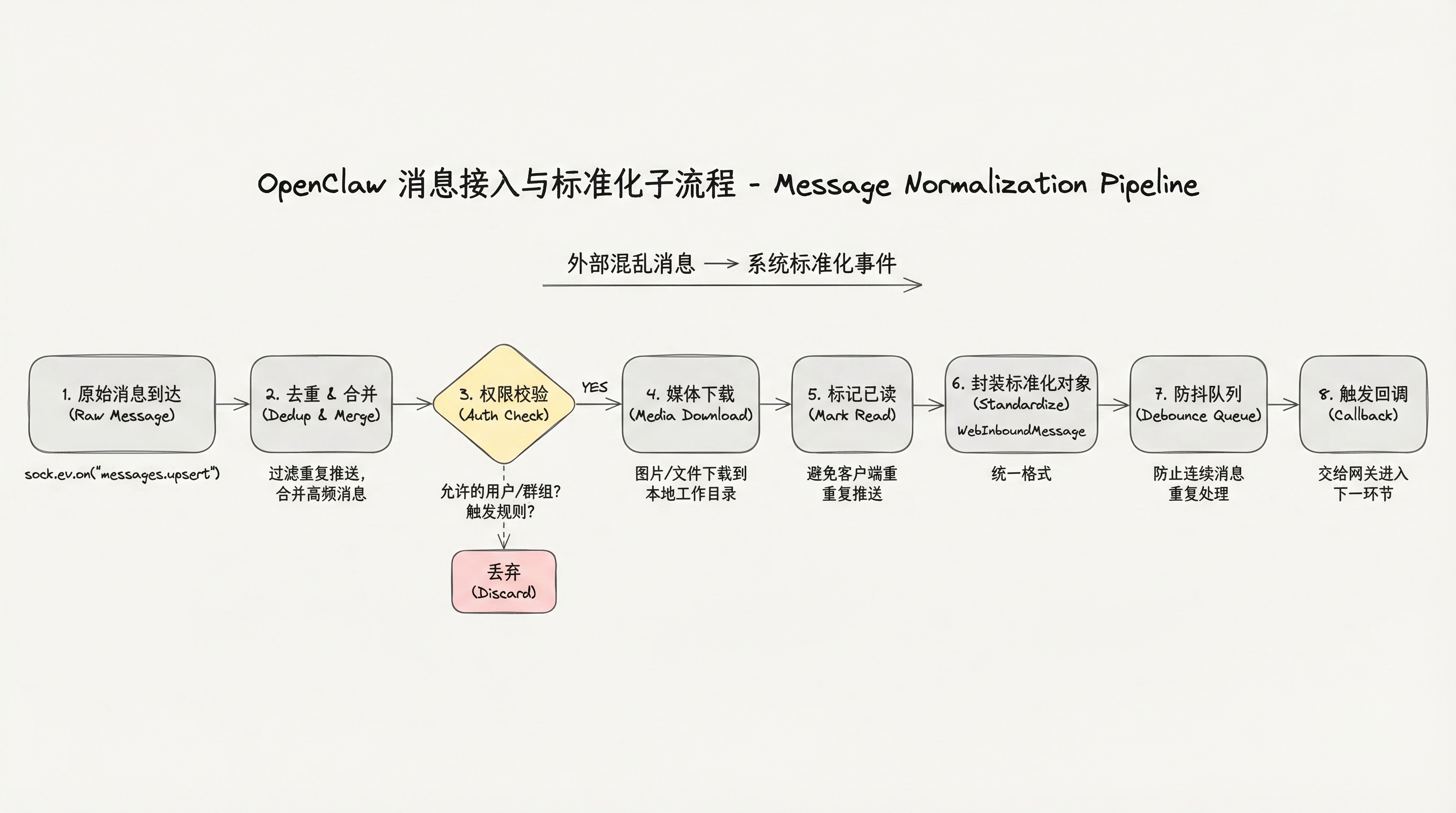
第二层:消息接入与标准化
源文件:extensions/whatsapp/src/inbound/monitor.ts
用户消息进入 OpenClaw 的第一站,并不是直接被转发给大模型,而是先进入消息监听与接入层。
系统通过 sock.ev.on("messages.upsert") 这个事件监听器持续监听新消息,一旦有消息到达,立刻启动以下流程:
2.1 消息去重与高频合并
真实的即时通讯环境中,平台经常重复推送消息,用户也可能短时间内连续发送多条。如果直接处理原始消息,很容易导致机器人重复回复。这一步的去重和合并,就是为了过滤噪声,保证后续流程拿到干净、完整的用户需求。
2.2 权限与合法性检查
判断消息是否来自允许的用户或群组,是否满足预设的触发规则。不符合规则的消息会被直接过滤,根本不会进入智能体处理流程。
2.3 媒体文件预下载
如果用户消息中包含图片、文件等媒体附件,系统会自动下载并保存到本地工作目录,供后续智能体推理时直接访问,完成图片分析、文档读取等操作。
2.4 封装为标准化对象
这是整个接入层最关键的一步:把来自不同即时通讯平台、格式千差万别的原始消息,统一封装成 WebInboundMessage 对象,即系统内部的标准化消息结构。
2.5 放入防抖队列
标准化后的消息被放入防抖队列,防止用户短时间内连续发送大量消息导致系统重复处理,之后触发回调函数,将整理好的消息交给网关进入下一环节。
本层本质:把来自外部世界混乱的、非标准化的用户消息,转化成系统内部可识别、可调度、可处理的标准化事件。
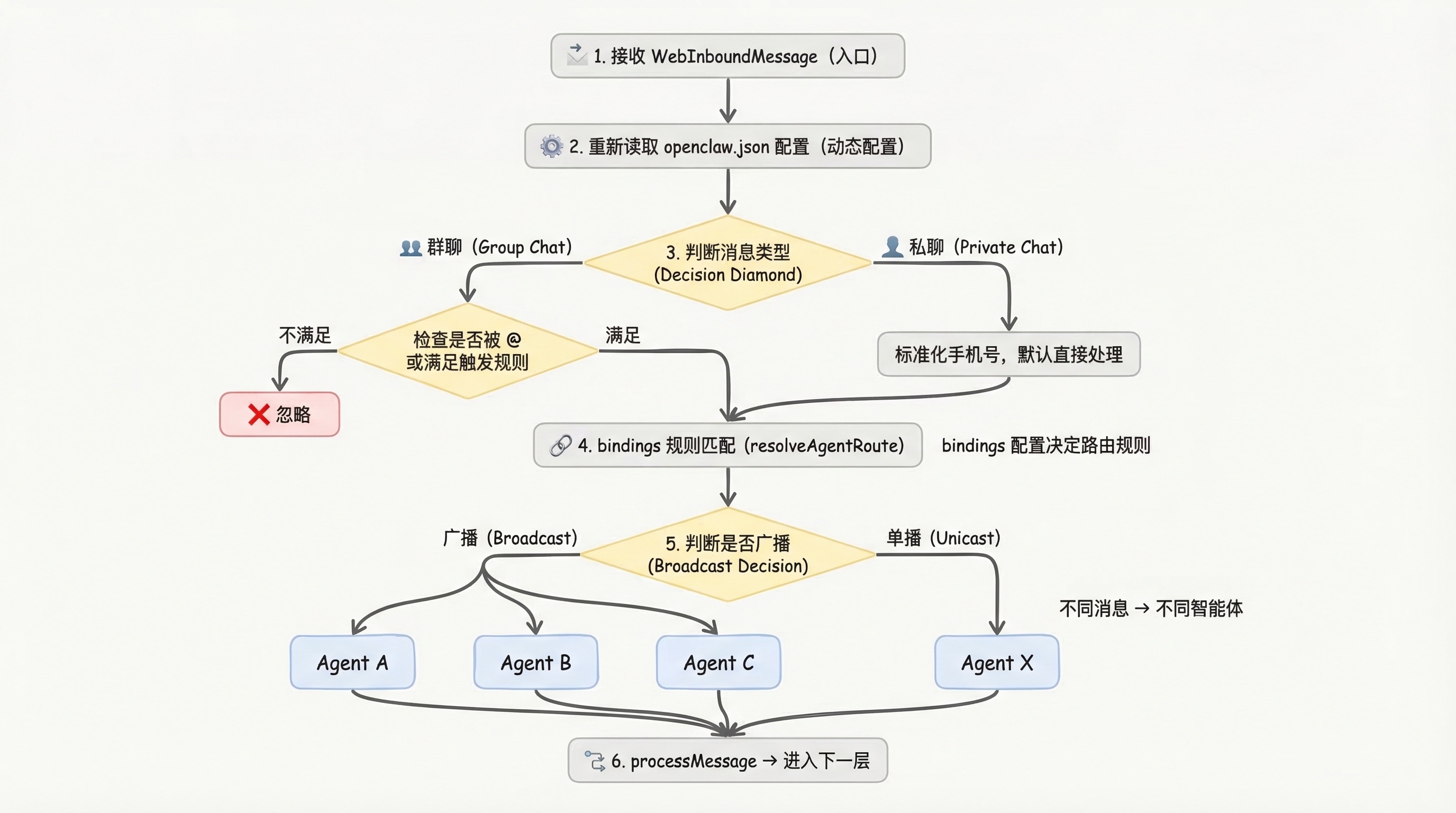
第三层:消息路由与智能体分发
源文件:extensions/whatsapp/src/auto-reply/monitor/on-message.ts
拿到标准化的 WebInboundMessage 对象后,进入路由模块。
并不是所有用户消息都会被送到同一个 AI 模型,由模型自己决定怎么处理。OpenClaw 的设计是:不同类型的任务,会被分配给不同的智能体来处理。
3.1 动态加载配置
系统通过 createWebOnMessageHandler 函数创建消息处理入口,同时重新读取最新的系统配置。这是一个关键的工程细节:OpenClaw 的配置支持动态调整,智能体绑定关系、权限规则等都可以在运行时修改,每次处理消息时重新读取配置,确保用的是最新规则。
3.2 解析消息方向
判断消息来自一对一私聊还是群组聊天,同时确定发送者的唯一 ID。群聊场景下,机器人需要判断是否被 @ 或满足触发规则;私聊场景下,通常默认直接处理。
3.3 智能体路由决策
读取 openclaw.json 配置文件里的 bindings(绑定规则),通过 resolveAgentRoute 函数,判断应该由哪个智能体处理当前消息。这样,不同渠道、不同用户、不同类型的消息,都可以被精准分流到对应的智能体。
3.4 生成会话历史键值
通过 buildGroupHistoryKey 函数,为当前会话生成唯一的历史记录键值——这是实现上下文关联的核心。AI 之所以能"记得"之前的对话,就是因为系统在每次推理前,都会通过这个键值加载对应的历史对话记录。
3.5 安全检查
- Same-phone 模式:判断消息是否来自同一台设备,避免机器人对自己发出的消息形成循环回复
- echoTracker 回声追踪:过滤掉刚刚自己发送的消息,避免重复处理同步事件
3.6 广播判断
如果满足广播条件,系统让所有需要参与的智能体分别执行一次 processForRoute 路由处理函数;否则只调用一次对应的路由处理逻辑。
最终,消息进入核心处理函数 processMessage,传递给下一环节。
第四层:推理环境准备
源文件:src/auto-reply/reply/get-reply.ts
到了这一步,很多人以为系统已经开始调用大模型了——但事实上,它只是完成了所有幕后准备工作,为接下来的推理搭建好完整、干净、信息完备的运行环境。
4.1 最终确认智能体与模型
通过 resolveSessionAgentId 函数最终确定当前会话对应的智能体,以及本次推理要使用的 AI 模型。
4.2 准备工作目录
执行 ensureAgentWorkspace 函数,为当前智能体准备独立的工作目录。智能体运行时经常需要读写文件、下载附件、生成临时结果、执行工具命令,所以每个智能体都有自己的专属工作区。
4.3 媒体与链接深度解析
applyMediaUnderstanding:对图片内容进行深度解析,转化成文本信息applyLinkUnderstanding:对链接里的网页内容进行解析,转化成文本信息
让智能体在正式推理之前,就对用户发送的所有内容有全面完整的理解。
4.4 初始化会话状态
通过 initSessionState 函数,把对应的历史对话记录完整加载进来。这就是 AI"记忆"的本质——不是真的有记忆,而是每次推理前把历史对话重新加载到上下文里。
4.5 解析特殊控制指令
通过 resolveReplyDirectives 函数,解析消息里的特殊控制指令:
reset:重置会话model:指定使用的模型verbose:开启详细输出模式/think high:使用更高的推理强度/new:开启全新会话,不加载历史上下文
4.6 处理内联操作
通过 handleInlineActions 函数处理不需要 AI 推理就能直接完成的操作,比如简单的系统状态查询、内置管理命令。
所有准备工作完成后,进入 runPreparedReply 函数,把会话上下文、模型选择、工具环境、用户消息、运行配置等全部打包传递给后面的流程。
第五层:执行参数转换
源文件:src/auto-reply/reply/get-reply-run.ts
核心函数:runPreparedReply
这一层的作用,是把用户消息和所有配置参数,转换成完整的、大模型可以直接执行的运行配置。
- 最终判断当前消息是否需要进入 AI 推理流程(某些系统指令或已处理消息会在这里直接结束)
- 将会话信息整理成大模型可理解的提示词结构
- 根据用户指令调整模型运行配置(推理强度、会话模式等)
- 校验推理的思考等级和运行策略(简单问答 vs. 复杂多步骤任务规划)
- 处理会话里的消息队列,确保消息按正确顺序进入推理流程
完成后,将整理好的参数包传递给 agent-runner.ts,排队执行下一步流程。
第六层:智能体生命周期调度
源文件:src/auto-reply/reply/agent-runner.ts
这个文件负责管理智能体运行的完整生命周期,是 OpenClaw 保证系统稳定运行的核心调度中枢。
- 调用
runReplyAgent把消息放进对应的处理队列,标记为"正在处理",避免重复处理 - 执行
runMemoryFlushIfNeeded:在必要时自动保存当前会话的记忆状态
长会话记忆的核心机制:在长时间对话中,系统需要不断叠加历史会话信息。如果不控制上下文长度,很快会撑爆大模型的上下文窗口导致推理失败。OpenClaw 会在会话信息达到上下文窗口上限时,自动对历史内容进行压缩,然后持久化到记忆文件里——这就是长会话记忆机制的核心实现。
准备完成后,才进入真正的 AI 调用流程:runAgentTurnWithFallback 函数。
第七层:执行容错与失败降级
源文件:src/auto-reply/reply/agent-runner-execution.ts
核心函数:runAgentTurnWithFallback
这一层不仅负责调用模型,还内置了完整的失败重试和降级机制:
- 用
crypto.randomUUID给本次 AI 调用生成全局唯一标识 - 用
registerAgentRunContext注册本次调用的完整上下文,方便后续精准追溯 - 进入循环执行框架:模型调用失败时(网络问题、服务异常、接口限流),按预设策略重试或切换备用模型后端
- 执行
normalizeStreamingText:清理无意义的心跳标识、静默回复、空文本等噪声 - 进入
runWithModelFallback,判断执行路径:- CLI 模式:进入
runCliAgent,交给外部 CLI 后端执行(如 Claude Code、Codex CLI、Gemini CLI) - 嵌入式模式(默认):进入
runEmbeddedPiAgent
- CLI 模式:进入
这一层还会持续检查返回结果里的异常信号:会话损坏、上下文溢出、消息顺序错误等,确保不会在基础条件不符合的情况下强行执行模型调用。
第八层:嵌入式智能体准备
源文件:src/agents/pi-embedded-runner/run.ts
核心函数:runEmbeddedPiAgent
到了这一步,前面所有的准备工作全部完成:执行路径确认、模型选定、容错机制部署、上下文和参数打包完毕。
8.1 确认排队规则
resolveSessionLane:确认本次 AI 调用应该遵守哪条排队规则——会话级顺序执行,还是全局级统一调度。
8.2 确定输出格式
resolvedToolResultFormat:根据消息来自的渠道(WhatsApp、Telegram 等),确定最终输出内容的格式。不同平台的消息能力完全不一样,所以在调用模型之前就确定好适配格式。
8.3 补全模型细节
resolveModel:把当前要使用的模型的所有细节全部补齐,包括完整名称、上下文窗口大小、API 地址、调用方式、默认运行参数等。
8.4 多密钥轮询认证
系统不只使用一个固定的 API 密钥,而是遍历一组认证配置候选项,优先尝试第一个可用的 API 密钥。如果当前密钥认证失败,自动切换到下一个,直到找到可用密钥或遍历完所有候选项。这种多密钥轮询机制在生产环境里可以最大限度避免单密钥限流或失效导致的服务不可用。
8.5 发起单次 AI 调用尝试
通过 runEmbeddedAttempt 函数进行单次 AI 调用尝试,把提示词、会话历史、工具环境、模型参数、认证信息、工作目录全部交给底层的智能体运行时,正式向大模型发起请求。
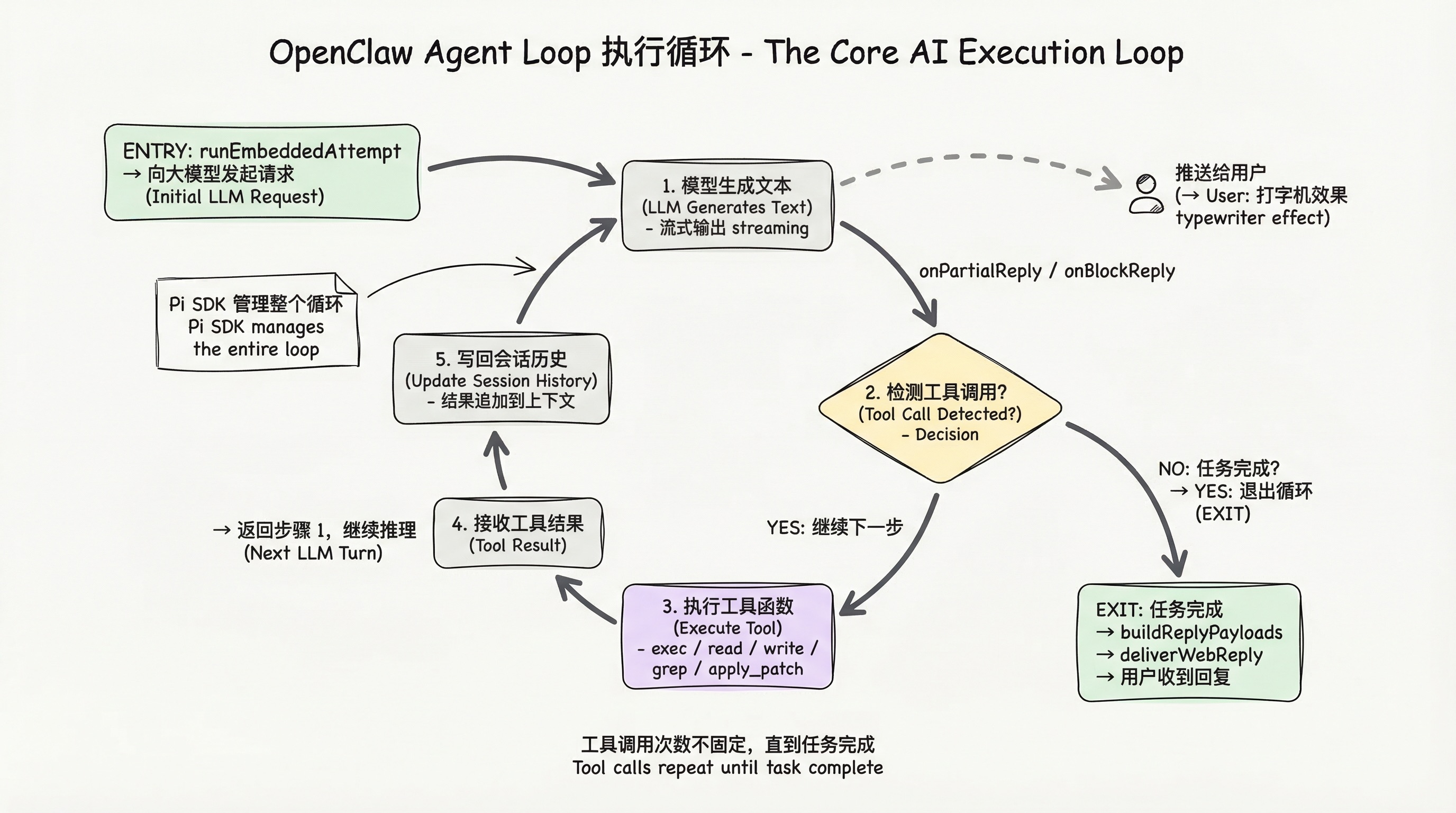
第九层:Agent Loop 执行循环
源文件:src/agents/pi-embedded-runner/run/attempt.ts
核心函数:runEmbeddedAttempt
这是整个流程里真正向大模型发起请求、完成核心推理的一步。
9.1 准备运行环境
通过 resolveUserPath 和 resolveSandboxContext 函数确定工作目录和沙箱边界,确保所有文件操作都在受控工作区内进行,不对用户系统造成非预期修改。
9.2 加载技能与上下文文件
加载当前智能体可用的所有技能和上下文文件。
9.3 创建工具集
执行 createOpenClawCodingTools 函数,创建智能体可以使用的所有工具:
- OpenClaw 自研工具:
exec(执行命令)、process(管理后台进程)、apply_patch(应用代码补丁)等 - Pi SDK 提供的工具:
read(读取文件)、write(写入文件)、edit(编辑文件)、grep(内容搜索)等
9.4 构建系统提示词
通过 buildEmbeddedSystemPrompt 和 buildAgentSystemPrompt 函数,读取大量运行时环境信息,拼接成一个非常长的结构化系统提示词——包括所有技能文档、项目说明文档、架构文档、灵魂设定文档,甚至每日生成的记忆文件。
大模型获得了更完整的环境信息,但也会消耗巨量 token;上下文过长时,反而会稀释模型注意力,导致抓不住核心需求,甚至触发上下文窗口溢出。这是 OpenClaw token 消耗过快、偶尔出现幻觉的核心原因之一。
9.5 创建智能体会话并发起请求
通过 Pi SDK 的 createAgentSession 函数创建智能体会话,把所有工具、上下文、规则绑定到会话里,再通过 applySystemPromptOverrideToSession 把系统提示词固定到本次会话。
最核心的一步:通过 activeSession.agent.streamFn 建立流式请求函数,调用 activeSession.prompt(effectivePrompt) 真正向大模型发送请求。
Pi SDK 负责管理整个 Agent Loop(智能体执行循环):
- 模型生成文本内容
- 触发工具调用
- 接收工具返回结果
- 把工具结果写回会话历史
- 继续下一轮推理生成
- 循环直到任务完成
9.6 流式分发
因为是流式生成,模型会逐段输出内容,系统通过 subscribeEmbeddedPiSession 订阅会话里的所有事件,在流式输出过程中触发 onPartialReply、onBlockReply 等回调函数,把每一段刚生成的内容立刻推送给前端消息渠道。
这就是我们在聊天窗口看到的"打字机效果"的底层实现:事件订阅 + 块级流式分发机制。
第十层:回复分发与发送
源文件:extensions/whatsapp/src/auto-reply/monitor/process-message.ts
核心函数:dispatchReplyWithBufferedBlockDispatcher
最后一步:接收 AI 已经生成好的回复内容,按照合适的方式发送回对应的聊天平台。
replyresolver:接收来自智能体运行层的所有结果(文本内容、工具调用信息、内容块 ID 等),转换成最终可以发送的回复结构deliverWebReply:根据当前使用的渠道(WhatsApp、Telegram 等),调用对应的平台接口,把整理好的回复内容推送给用户
在流式回复场景下,系统接收到每一段完整内容后就立刻发送出去,所以我们看到的回复是一段一段逐渐出现的,而不是等待很久后一次性显示完整答案。
当所有内容发送完成,这一轮的消息处理流程正式结束,整个系统回到初始监听状态,等待下一条用户消息。
总结:OpenClaw 的四个核心特质
经过以上十层的完整拆解,我们可以提炼出 OpenClaw 的四个核心特质:
1. 运行时装配体系
OpenClaw 最核心的价值,在于构建了一套完整的运行时装配体系,能把用户的一条消息精准嵌入到一个全维度的运行环境里。
2. 不生产智能,只搭建舞台
OpenClaw 本身并不生产智能——它把核心的智能生成任务完整交给了外部的 Pi SDK,自己却完成了鉴权校验、文件读写、工具管理、上下文装配、会话调度、渠道适配、异常处理等所有的"脏活累活",最后把整理好的数据喂给大模型的 SDK。
3. 提示词工程的极致实践
OpenClaw 把所有的运行时信息,全部显式地、结构化地翻译进了系统提示词里,是提示词工程做到极致的典型案例。
4. 本地优先的消息系统网关
从架构上看,OpenClaw 的前端对接了大量消息渠道,中间是统一的控制平面,底层挂载了智能体运行时、工具集、CLI 交互界面、记忆系统等。网关才是整个系统的控制平面,本质上它是一个网关系统。
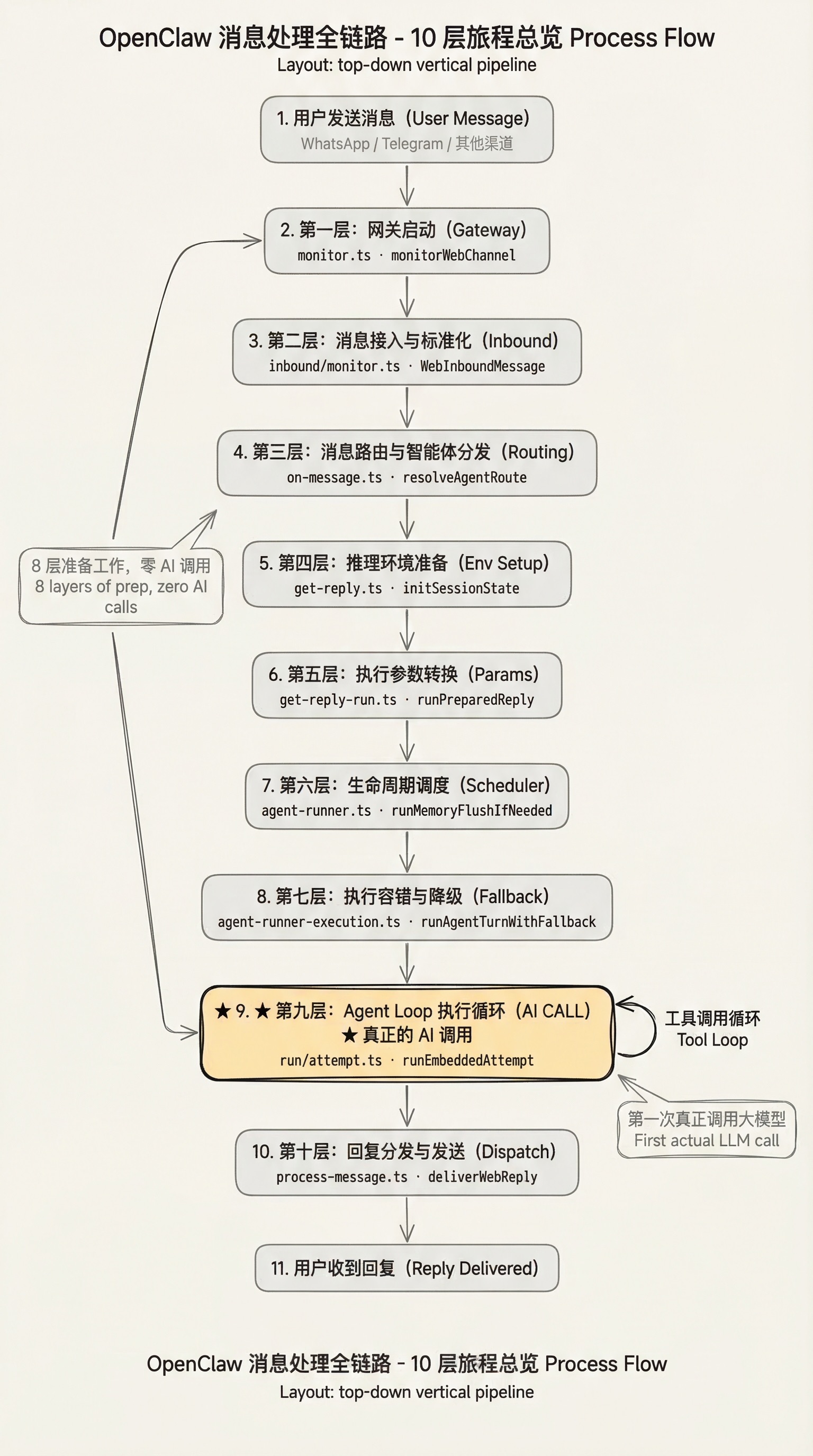
完整流程一览
用户发送消息
↓
[第一层] 网关启动与初始化 (monitor.ts)
↓
[第二层] 消息接入与标准化 (inbound/monitor.ts)
去重 → 权限校验 → 媒体下载 → 封装为 WebInboundMessage → 防抖队列
↓
[第三层] 消息路由与智能体分发 (on-message.ts)
动态配置 → 方向解析 → resolveAgentRoute → 会话键值 → 安全检查
↓
[第四层] 推理环境准备 (get-reply.ts)
确认智能体 → 工作目录 → 媒体解析 → 加载历史 → 解析指令
↓
[第五层] 执行参数转换 (get-reply-run.ts)
提示词结构化 → 运行配置调整 → 消息队列排序
↓
[第六层] 生命周期调度 (agent-runner.ts)
入队 → 记忆压缩持久化 → 触发 runAgentTurnWithFallback
↓
[第七层] 执行容错与降级 (agent-runner-execution.ts)
UUID 注册 → 失败重试 → 降级切换 → CLI/嵌入式路径选择
↓
[第八层] 嵌入式智能体准备 (pi-embedded-runner/run.ts)
排队规则 → 输出格式 → 模型补全 → 多密钥轮询
↓
[第九层] Agent Loop 执行循环 (run/attempt.ts)
沙箱环境 → 工具集 → 系统提示词构建 → 创建会话 → 发起请求
↕ (工具调用 ↔ 推理生成,循环直到任务完成)
↓
[第十层] 回复分发与发送 (process-message.ts)
结果整理 → 格式适配 → 推送到即时通讯平台
↓
用户看到回复
理解了这套完整的执行链路,你会发现 OpenClaw 真正厉害的地方,不在于它调用了多么先进的 AI 模型,而在于它用工程化的方式,把"让 AI 真正可用于生产环境"这件事,做得非常扎实。