当我们谈论 Agent Infra 时,我们到底在谈什么?
目录
引言
Agent 基础设施毫无疑问是当下 VC 投资中最火热的方向之一。我个人也在这个领域下注——但与大多数 VC 不同的是,我是以基础设施使用者和构建者的身份进入这个领域的。正因如此,我想从一个经常被忽视、却非常基础的问题出发:
当我们谈论 Agent Infra 时,我们到底在谈什么?
这篇文章不讨论什么
首先,先划清边界。这篇文章不是在讨论通用 AI 基础设施——无论是预训练、后训练 RL,还是推理基础设施。这些都不在本文的讨论范围内,说实话,我对它们兴趣也不大。
这些系统大多服务于训练流程,不管是预训练还是 RL。模型训练本质上是一次性或按代进行的活动,这意味着围绕它构建的许多支撑系统天生就是"可丢弃"的。
而推理基础设施则已经高度商品化,在产品层面几乎没有太多创新空间。
真正的机遇
真正让我感兴趣的是:推理基础设施之上的东西。
随着 Agent 开始接管越来越多的工作,我相信在"推理之上、Agent 之下",会出现一个全新的基础设施层——一个专门为 Agent 的执行与协作而设计的运行时层。
当前默认的 Agent 架构
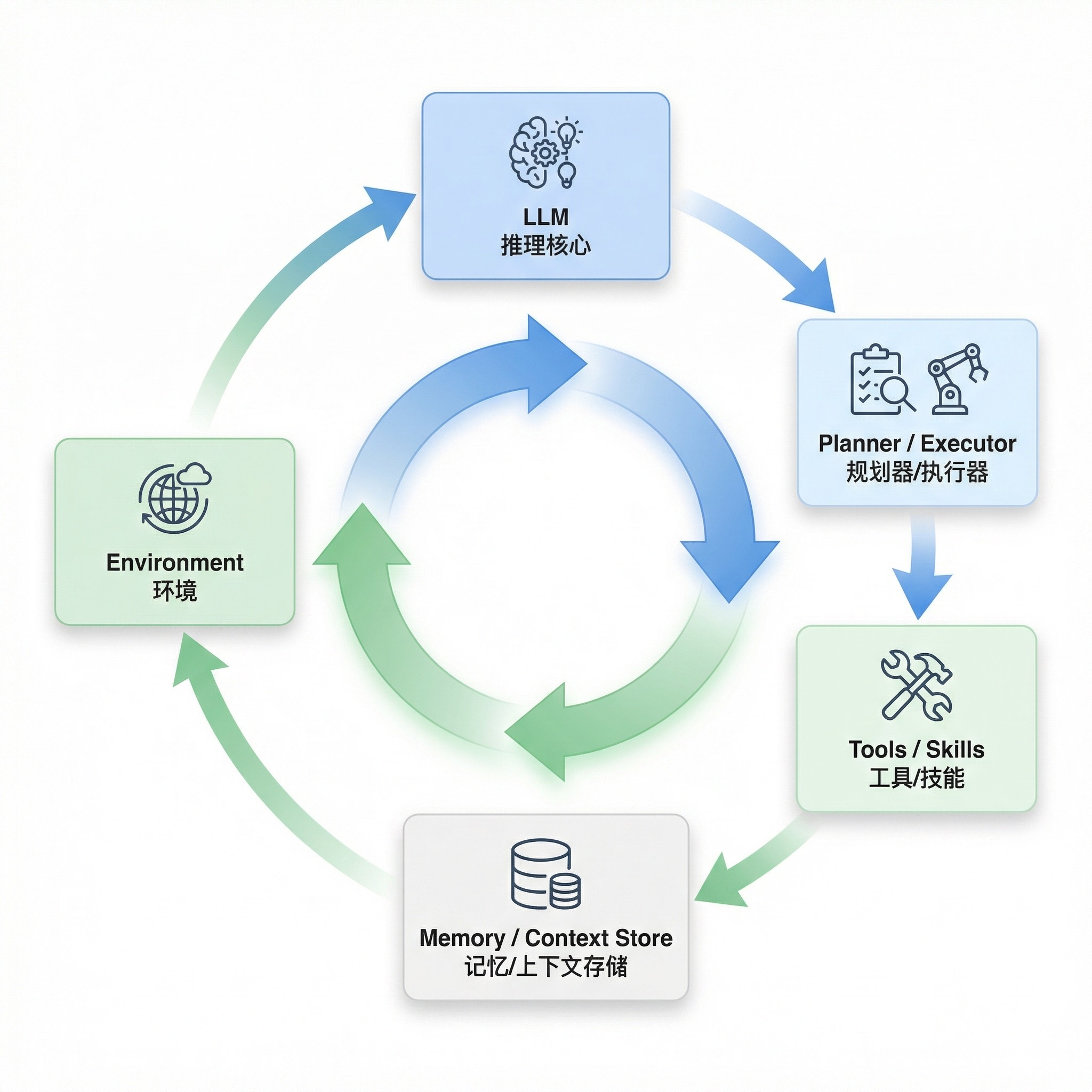
我们先对齐一下大多数人心中"默认"的 Agent 架构。一个典型的 Agent 系统通常包含以下组件:
五个核心组件
-
LLM / 推理核心
- 负责理解上下文、生成计划、决定下一步行动
-
Planner / Executor(规划器 / 执行器)
- 将复杂目标拆解为步骤,并逐步执行
-
Tools / Skills(工具 / 技能)
- 封装的外部能力,例如调用 API、执行代码、访问数据库、浏览网页等
-
Memory / Context Store(记忆 / 上下文存储)
- 存储中间状态、历史行为、长期偏好等
-
Environment(环境,通常是隐式的)
- 动作被执行的真实或虚拟世界
Agentic Loop
这些组件运行在一个持续循环中——也就是 Agentic Loop,这几乎是当今所有 Agent 所采用的架构。
当前架构的问题
虽然这个架构在概念上清晰,但在实践中存在多个关键瓶颈,限制了 Agent 系统的能力和效率。
顺序执行是天然瓶颈
我之前已经写过相关内容。即使规划是完美的,大多数 Agent 仍然按如下方式执行任务:
一步 → 等结果 → 下一步
这是一个高度顺序化的执行模型。即便使用了子 Agent,任务分发的粒度也通常非常小。
问题表现
- 动作之间的强依赖使并行几乎不可能
- 任意一步失败都会阻塞整个执行路径
- 对探索型任务极其低效
关键洞察
我强烈直觉认为:大规模探索是解决真正复杂任务的关键。
举个例子,在我优化 Coding Agent 工作流时,目标是让 Agent 在尽可能长的时间内自主运行、无需人工干预。但"没有方向的自主"是毫无意义的,真正的关键在于:让 Agent 能持续探索多种可能性、总结结果、并迭代改进。
如果探索本身是低效的,整体吞吐和质量都会迅速崩溃。
Agent 协作的极限
我们已经见过许多 Agent 协作的尝试:通信协议、协调框架、多 Agent 系统。MCP、A2A 是其中比较有代表性的例子——但它们都谈不上真正成功。
今天的 Agent 协作,更像是"勉强能对话的 Agent",离真正的协作还差得很远。
协议的局限
当然,人们在积极推动 A2A 类方案,想法本身也没错:Agent 应该能委派任务、汇报进度、动态协作。
问题在于:协议本身并不够。
A2A 只是定义了"应该发生什么",却没有回答"如何构建一个真正可用的系统,让这些事情真的发生"。中间仍然缺失一个关键层,而到目前为止,还没有一个真正可用的平台。
长时间任务中的环境退化
还有一个我认为极其重要、却被严重低估的问题。
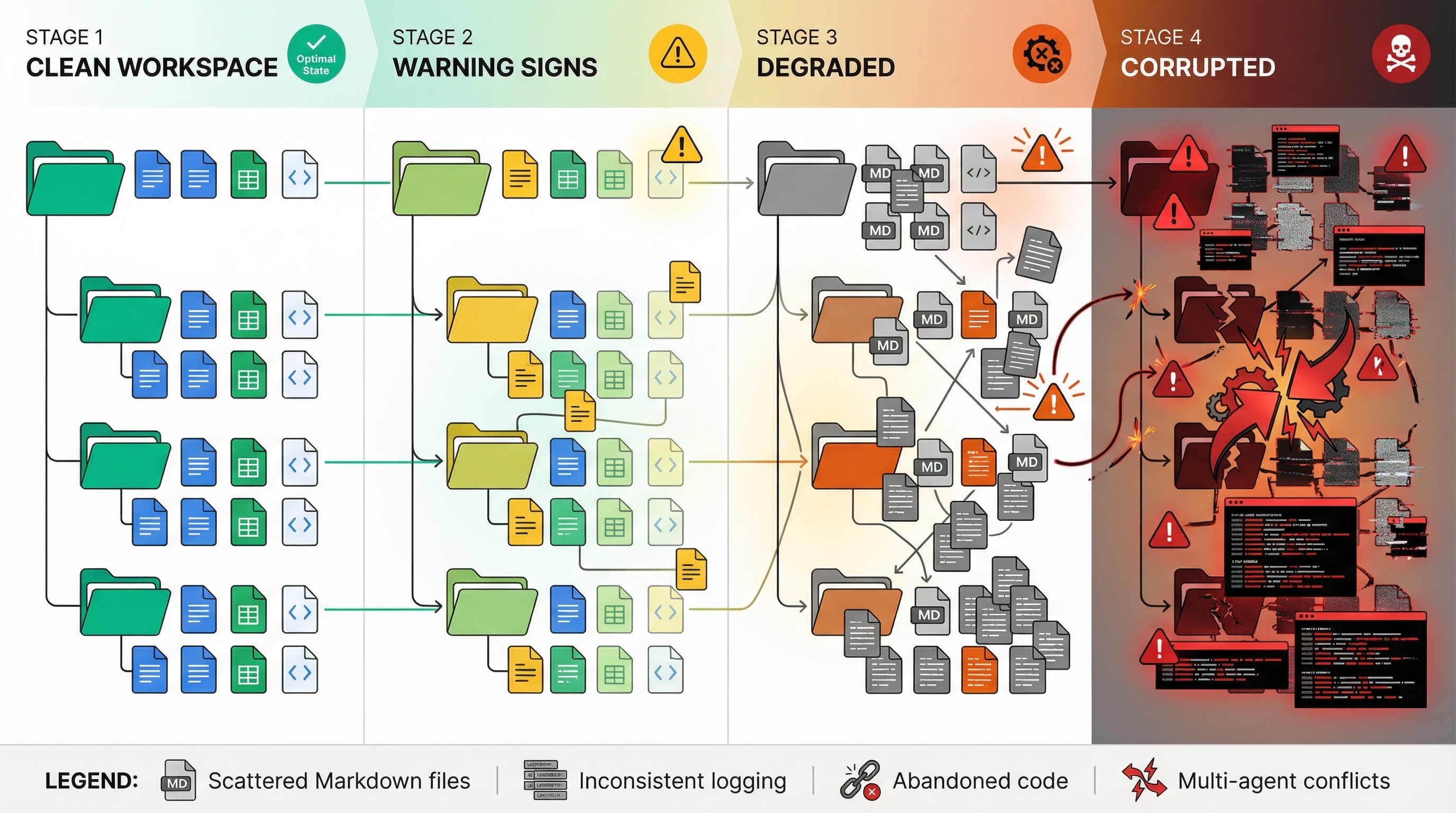
如果你的系统无法提供原子化、无副作用的动作,那么在复杂任务执行过程中,环境几乎必然会逐步退化。
问题的根源
这在 Demo 中并不明显。但在任何长链路、多步骤、探索型工作流中,几乎是必然发生的。
现实世界中的大多数动作都具有强副作用。一旦第一个动作执行,环境就已经被"污染"了。随着动作不断叠加,状态累积、错误放大、失败路径与成功路径交织在一起,最终 Agent 根本无法判断当前环境真实处于什么状态。
到那时,无论规划器多聪明、推理能力多强,Agent 都是在一个不断腐化的环境中做决策。
现实案例:Coding Agent
Coding Agent 是最典型的例子。把它们放进一个真实的大型代码库,很快就会出现同样的模式:
- 工作区变得混乱
- 随机的 Markdown 文件到处都是
- 日志风格不统一
- 临时代码没人清理
- 多个子 Agent 在同一目录互相覆盖修改
这就是环境退化的教科书案例。
现有的变通方案:Git Worktree
工程师们已经找到了一种粗糙但有效的变通方案:Git worktree。
每个子 Agent 拥有一个隔离的 worktree,在最小化的环境中完成任务,只通过 diff 或 PR 的形式返回结果。
本质上,这是一种低成本的方式,用来提供隔离、可丢弃的执行环境。它很接近正确答案,但它无法规模化,也无法泛化。
通往物理世界的"最后一公里"
表面上看,今天的 Agent 已经很强大了。但一旦你让它们做一些没有干净 API 的事情,一些真正影响现实世界的操作,体验立刻变得脆弱不堪。
试着让 Agent 去下单、付款、订酒店。
Skills 的局限
Skills 是一个很好的抽象——我也非常喜欢它。在纯软件场景下,它们表现不错。但一旦任务进入物理世界,这个抽象就开始失效。
现实世界充满了隐式状态:登录会话、权限、风控、UI 变化、临时校验、重试机制。人类可以直觉性地处理这些,但它们几乎从未被封装成干净的执行模型。
结果是:Agent 的每一步操作都会在环境中留下"残留",而这些残留又会反过来影响后续规划。
未来展望
我怀疑,Skills 很快会从"软件操作"扩展到诸如"买菜 Skill""买咖啡 Skill"这类能力。只有这样,Claude Cowork 这样的产品才能真正发挥潜力。
一个可能的方向:Box 抽象
问题的既视感
这些问题让我产生了一种强烈的既视感。
在过去十多年里,DevOps 和云计算在从单机系统迈向大规模分布式架构时,曾遇到过几乎一模一样的挑战。
早期系统不稳定、难以调试、不可复现。在单机上还能勉强应付,一旦到 1000 台机器,状态爆炸就成了致命问题。
最初我们责怪人:流程不规范、运维粗心、文档不完整。后来才意识到,真正的问题并不在于人,而在于缺乏稳定的执行基础。
云计算的解决方案
容器、不可变基础设施、基础设施即代码、声明式配置,并没有让软件更聪明,但它们让环境变得可控:
- 失败可复现
- 部署可重复
- 操作可幂等
历史的重复
当我今天看 Agent Infra 时,感觉我们正站在同一个拐点上。
Agent 并不缺智能,它们被迫在不稳定、不可预测的环境中工作。
引入 Box
我的第一个建议其实很简单:将 Skill 与其执行环境绑定在一起。
引入一个新的抽象,我们称之为 Box。
Box 的定义
一个 Box:
- 不暴露任何执行细节
- 没有外部依赖
- 没有副作用
- 封装了 Skill 引导的动作 + 可复现、可丢弃的环境
Box 解决的是单一环境内的执行质量问题。由于它是由 Skill 定义的,因此可以组合、继承。
实际例子
例如,"给我买一杯咖啡"可以拆解为原子级 Skills:
- 打开浏览器 → Box1
- 登录我的账号 → Box2
- 下单买咖啡 → Box3
这些可以组合成一个 "Buy Coffee" Box,前两个 Box 甚至可以被缓存。
Claude 只需要写:
box3 = box1 + box2
box3.spawn().buy_coffee('latte')
咖啡买完后,Box 被销毁——本地环境不会被污染。
Box vs Docker
与 Docker 不同,Box 的环境是纯粹的、轻量的、完全语义化的,没有任何技术细节向上泄漏。

从编码到物理世界
这种方式不仅解决了 Coding Agent 的"最后一公里"问题,还能走得更远——它弥合了代码与现实世界之间的鸿沟。
对于"买咖啡""找并预订最便宜的酒店"这类任务,等待 API 出现并不现实。
Box 是一次尝试:把物理世界编码化。
一旦我们拥有足够多的 Box 函数,编程现实世界将变成 Agent 最擅长的事情。
已有的探索
已经有一些前沿创业公司在探索类似方向,例如:
Agent 的 Kubernetes
如果每个动作都运行在可复现、可丢弃的 Box 中,下一个问题几乎是必然的:
- 谁来创建 Box?
- 谁来调度它们?
- 谁来监控它们?
- 谁来决定重试、放弃,还是分叉执行路径?
答案再次来自云基础设施。
Kubernetes 成为了容器编排的事实标准。那么,Agent 的 Kubernetes 会是什么样?
理想的基础设施层
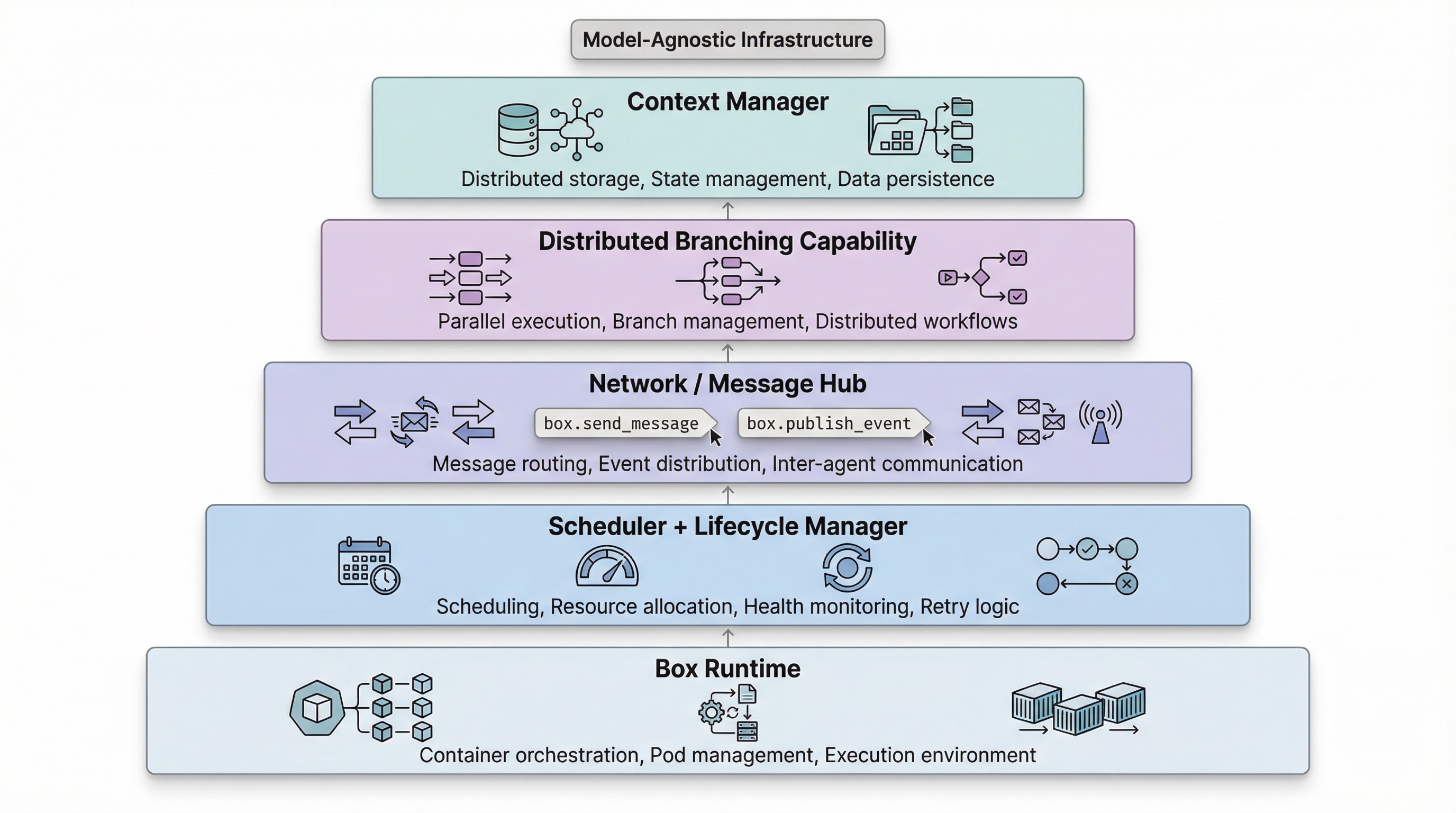
我认为它应该是一个与模型无关的基础设施层,包含以下组件:
1. Context Manager(上下文管理器)
基于分布式数据库和分布式文件系统。数据库管理结构化的共享上下文(如对话历史,用于 prompt 构造),文件系统则提供 Agent 工作区之外的协作空间。
2. 一等公民的"分支"能力
这不是 Git 分支或 worktree,而是系统级的执行分支机制。多个 Agent(或同一个 Agent)可以在共享目标的前提下,同时探索不同路径,且互不产生副作用。
元数据由数据库管理,分支文件系统提供底层支撑。
3. 网络内消息 / 通信枢纽
嵌入到每个 Box 运行时中:
box1.send_message(box2, 'hello')
box1.publish_event('buy_coffee_success')
box2.on_event('buy_coffee_success', on_success)
4. 调度器 + 生命周期管理器
负责资源放置、并发控制、重试、超时、取消以及失败策略。
在容器世界里,Kubernetes 每天都在做这些事;而在 Agent 系统中,大多数团队仍然把这些逻辑硬编码进框架里,反复造轮子,可靠性却参差不齐。
5. Box Runtime
也就是前面描述的执行环境。
结语
到这个阶段,我认为已经没必要再反复强调模型会变得多么聪明。
决定 Agent 能否胜任复杂任务的,并不仅仅是智能水平,而是:
- 执行是否可控
- 失败是否廉价
- 环境是否可替换
- 协作是否由基础设施保障
借鉴历史
Agent Infra 面临的挑战并不新。我们在其他领域已经遇到过,也部分解决过。
现在剩下的,是将这些经验重新组织,并应用到这个新的运行时层之上——Agent Runtime。