kafka
kafka初体验
kafka 是支持 一个 consumer 监听多个 topic 的。
这就导致 如果业务上不需要 某个 consumer 去监听多个topic 就要保证该 consumer 的 groupId 唯一。
也就是说 topic A 的一个 consumer groupId 是 :test 那对于topic B 的一个 consumer groupId 就不能是 test (除非你需要 test 这组 consumer 监听 topic A 和 topic B);
不然就会导致 zk 频繁的 reblance
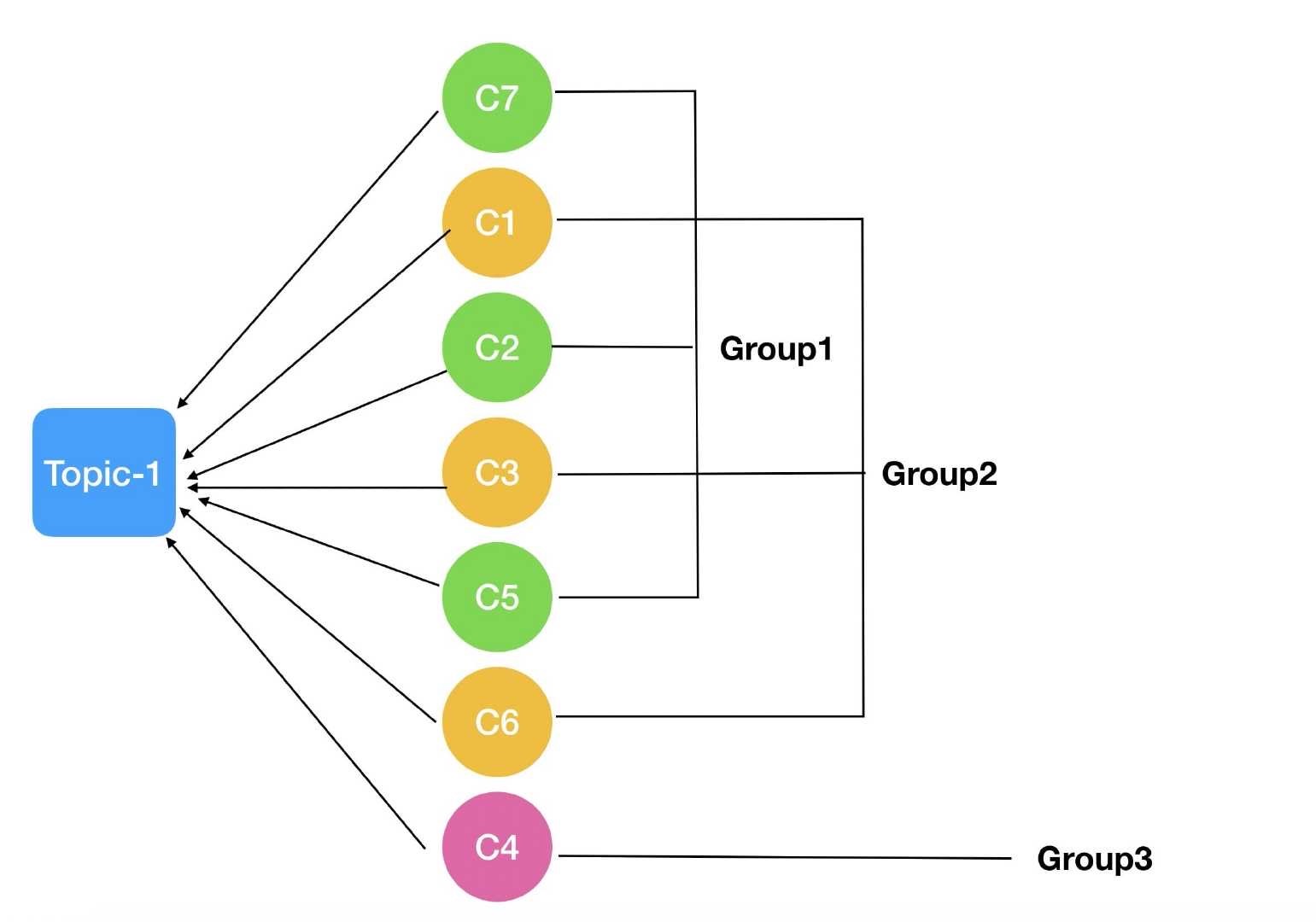
对应同一个topic可以任意添加消费者,如果消费者之间的group相同就是在一个组里面, 在一个组的消费者之间是竞争关系,只有一个消费者可以消费这个topic的一条消息。
如果有多个 group 那group之间是平级关系,每一个 group都可以接受到消息。
kafka 默认存放7天的临时数据,如果遇到磁盘空间小,存放数据量大,可以设置缩短这个时间。
1. 什么是 Kafka
Kafka 是一个分布式流式平台,它有三个关键能力
1、订阅发布记录流,它类似于企业中的消息队列或企业消息传递系统 2、以容错的方式存储记录流 3、实时记录流
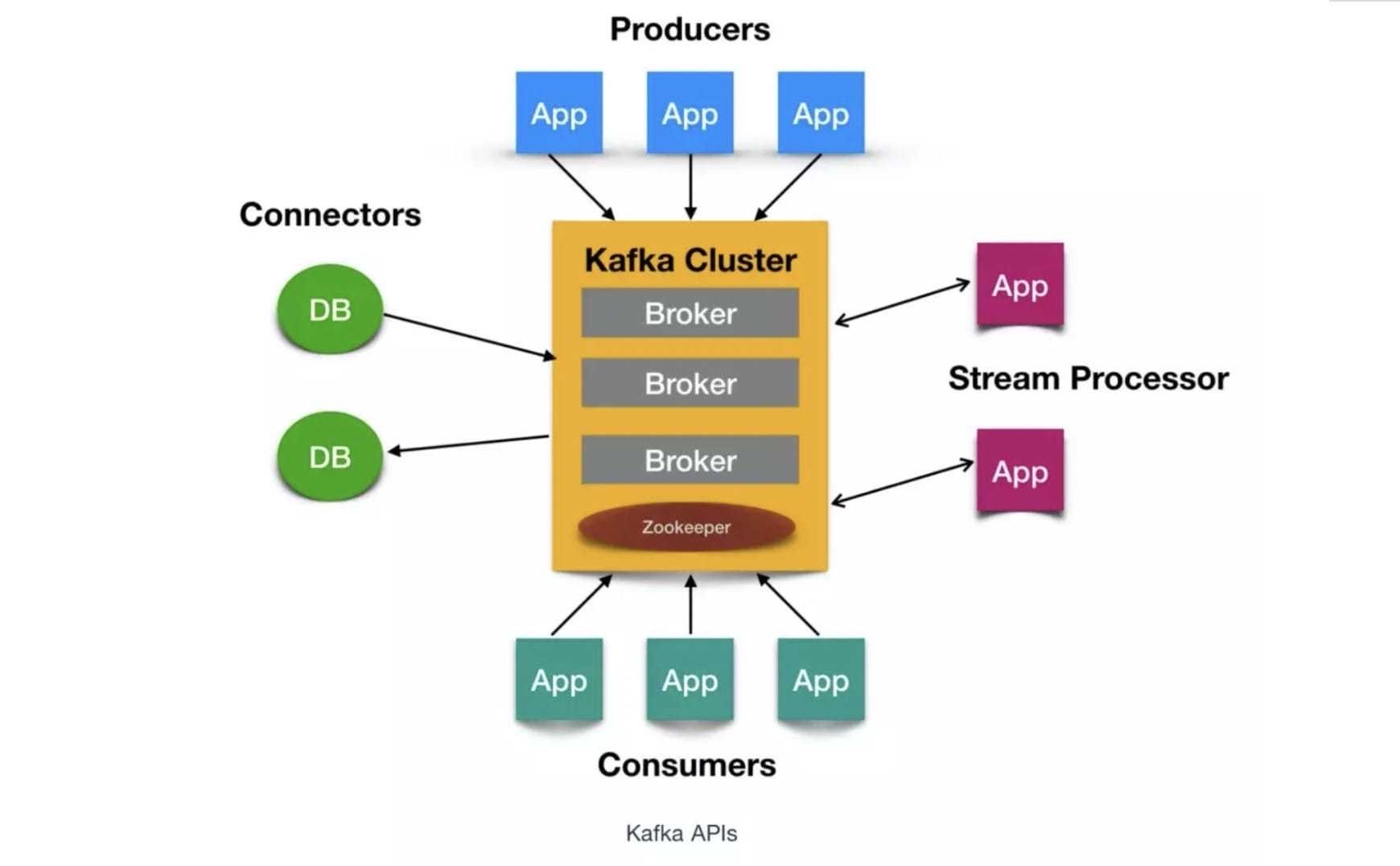
2. kafka 核心 APIs
Kafka 有四个核心API,它们分别是
1、Producer API,它允许应用程序向一个或多个 topics 上发送消息记录 2、Consumer API,允许应用程序订阅一个或多个 topics 并处理为其生成的记录流 3、Streams API,它允许应用程序作为流处理器,从一个或多个主题中消费输入流并为其生成输出流,有效的将输入流转换为输出流。 4、Connector API,它允许构建和运行将 Kafka 主题连接到现有应用程序或数据系统的可用生产者和消费者。例如,关系数据库的连接器可能会捕获对表的所有更改
3. kafka 重要概念
topic
topic 被称为主题,在 kafka 中,使用一个类别属性来划分消息的所属类,划分消息的这个类称为 topic。topic 相当于消息的分配标签,是一个逻辑概念。主题好比是数据库的表,或者文件系统中的文件夹。
partition
partition 译为分区,topic 中的消息被分割为一个或多个的 partition,它是一个物理概念,对应到系统上的就是一个或若干个目录,一个分区就是一个 提交日志。消息以追加的形式写入分区,先后以顺序的方式读取。分区可以分布在不同的服务器上,也就是说,一个主题可以跨越多个服务器,以此来提供比单个服务器更强大的性能。
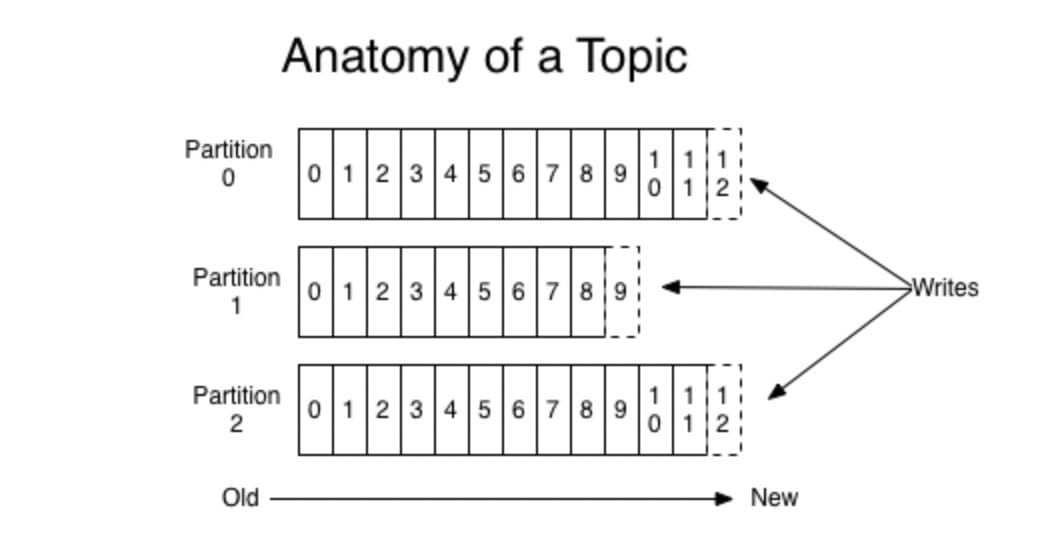
==注意:由于一个主题包含无数个分区,因此无法保证在整个 topic 中有序,但是单 partition 分区可以保证有序。消息被迫加写入每个分区的尾部。Kafka 通过分区来实现数据冗余和伸缩性==
segment
Segment 被译为段,将 Partition 进一步细分为若干个 segment,每个 segment 文件的大小相等。
borker
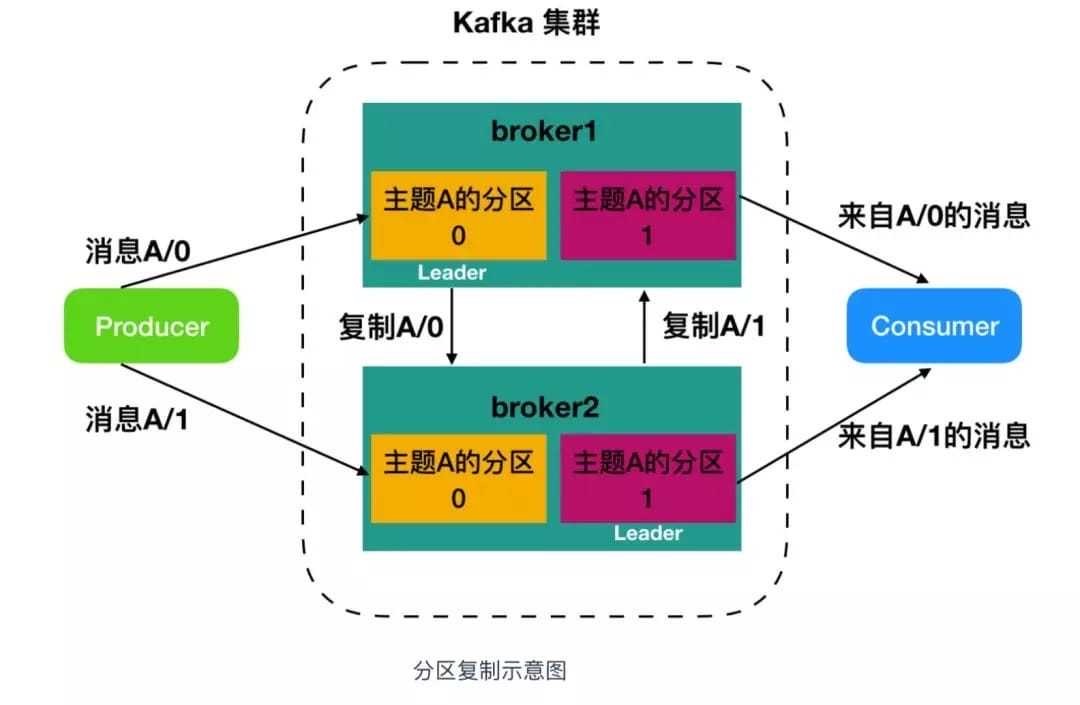
Kafka 集群包含一个或多个服务器,每个 Kafka 中服务器被称为 broker。broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
broker 是集群的组成部分,每个集群中都会有一个 broker 同时充当了 集群控制器(Leader)的角色,它是由集群中的活跃成员选举出来的。每个集群中的成员都有可能充当 Leader,Leader 负责管理工作,包括将分区分配给 broker 和监控 broker。集群中,一个分区从属于一个 Leader,但是一个分区可以分配给多个 broker(非Leader),这时候会发生分区复制。这种复制的机制为分区提供了消息冗余,如果一个 broker 失效,那么其他活跃用户会重新选举一个 Leader 接管。
producer
生产者,即消息的发布者,其会将某 topic 的消息发布到相应的 partition 中。生产者在默认情况下把消息均衡地分布到主题的所有分区上,而并不关心特定消息会被写到哪个分区。不过,在某些情况下,生产者会把消息直接写到指定的分区。
consumer
消费者,即消息的使用者,一个消费者可以消费多个 topic 的消息,对于某一个 topic 的消息,其只会消费同一个 partition 中的消息
producer 生产者概述
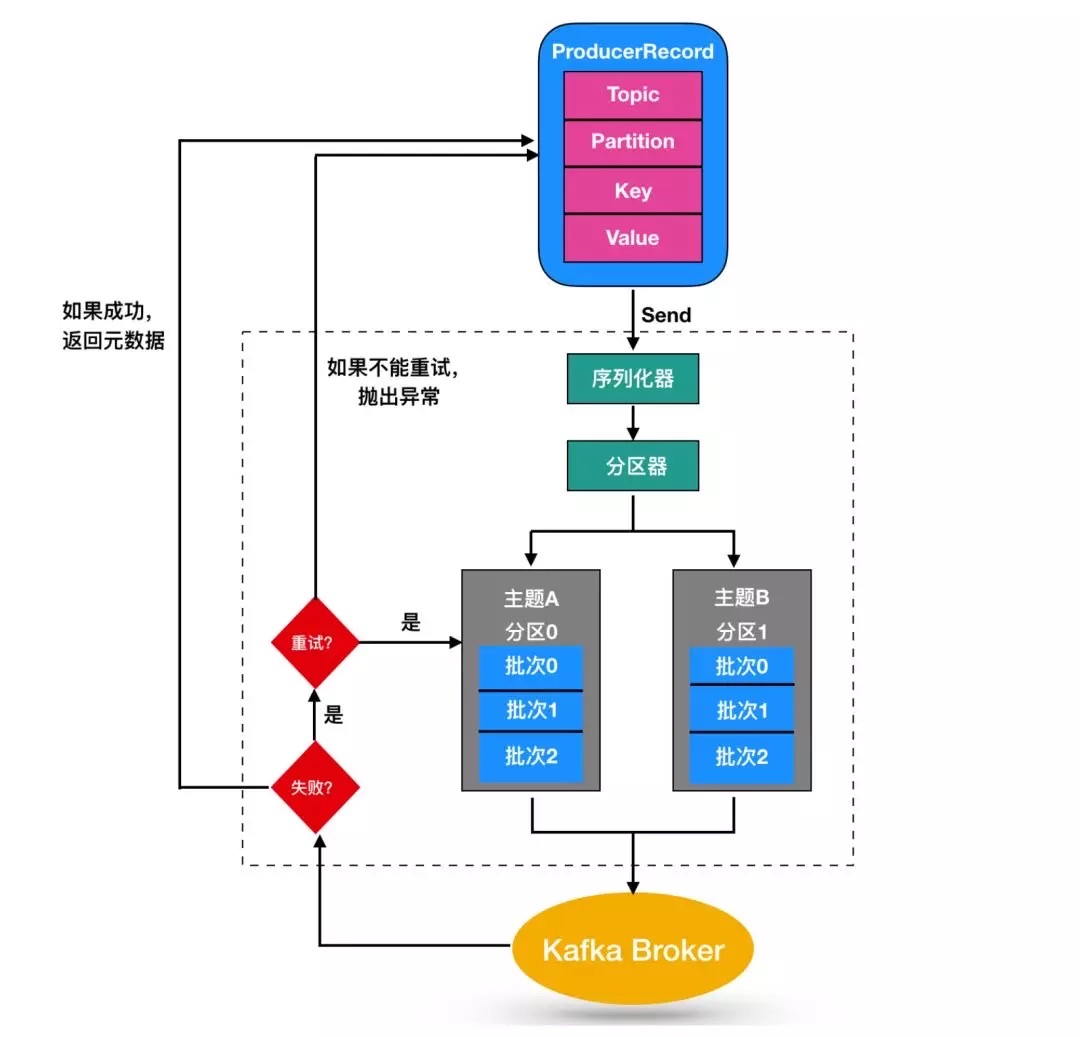
创建 Kafka 生产者
要往 Kafka 写入消息,首先需要创建一个生产者对象,并设置一些属性。Kafka 生产者有3个必选的属性
- bootstrap.servers
该属性指定 broker 的地址清单,地址的格式为 host:port。清单里不需要包含所有的 broker 地址,生产者会从给定的 broker 里查找到其他的
broker 信息。不过建议至少要提供两个 broker 信息,一旦其中一个宕机,生产者仍然能够连接到集群上。
- key.serializer
broker 需要接收到序列化之后的 key/value值,所以生产者发送的消息需要经过序列化之后才传递给 Kafka Broker。生产者需要知道采用何种方式把
Java 对象转换为字节数组。key.serializer 必须被设置为一个实现了org.apache.kafka.common.serialization.Serializer
接口的类,生产者会使用这个类把键对象序列化为字节数组。这里拓展一下 Serializer 类
Serializer 是一个接口,它表示类将会采用何种方式序列化,它的作用是把对象转换为字节,实现了 Serializer
接口的类主要有 ByteArraySerializer、StringSerializer、IntegerSerializer ,其中 ByteArraySerialize 是 Kafka
默认使用的序列化器,其他的序列化器还有很多,你可以通过 这里 查看其他序列化器。要注意的一点:**key.serializer 是必须要设置的
**。
- value.serializer
与 key.serializer 一样,value.serializer 指定的类会将值序列化。
下面代码演示了如何创建一个 Kafka 生产者,这里只指定了必要的属性,其他使用默认的配置
Properties properties=new Properties();
properties.put("bootstrap.servers","broker1:9092,broker2:9092");
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer=new KafkaProducer<>(properties);
向 kafka 发送消息
ProducerRecord<String, String> record=new ProducerRecord<>("topic","key","value");
Future<RecordMetadata> result=kafkaProducer.send(record);
ProducerRecord 的 key 值是非必填的,因为Kafka 客户端是以整个 record 作为一条消息进行发送的,key 值的作用是用于 kafka 计算将该条消费存放在哪个 partition上,如果不指定 key,即默认为 null 会随机的将消息存放于某个 partition 上。
If the key is null, then the Producer will assign the message to a random Partition.
以上是同步发送消息,还可以异步发送,只需要提供一个回调函数即可:
kafkaProducer.send(record,(metadata,exception)->{
if(exception!=null){
System.out.println(exception.getMessage());
}
});
生产者分区策略
上面讲过 kafka 会依据 producerRecord 中指定的 key 将该条消息分配到某个 partition
中,这就涉及到分区策略。可以实现org.apache.kafka.clients.producer.Partitioner 接口,自定义分区策略。并配置到 producer中。
props.put("partitioner.class","com.yuhaowin.mypartitioner");
KafkaConsumer kafka 消费者
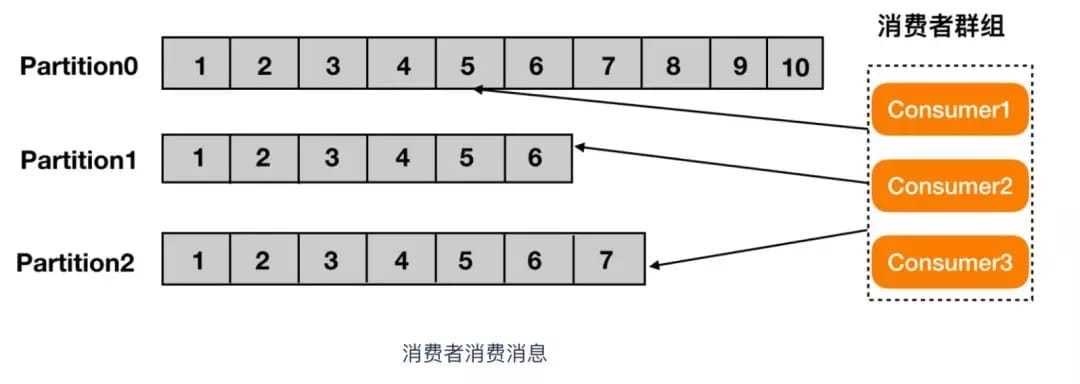
要从 kafka 的 topic 中获取到消息,就需要用到 kafkaConsumer 这个类,kafka 的消费者是从属于消费组的,一个群组里的消费者订阅的都是相同 topic 的消息,每一个消费者接收 topic 一部分分区的消息。如图:
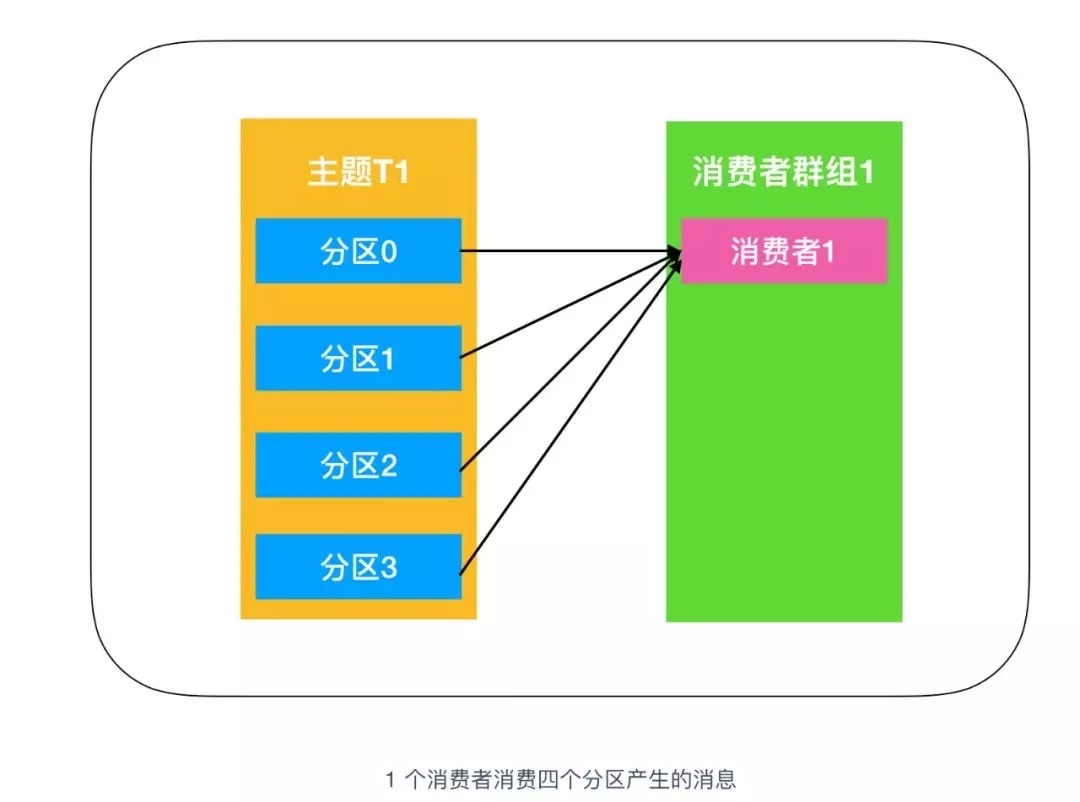
上图中的主题 T1 有四个分区,分别是分区0、分区1、分区2、分区3,我们创建一个消费者群组1,消费者群组中只有一个消费者,它订阅主题T1,接收到 T1 中的全部消息。由于一个消费者处理四个生产者发送到分区的消息,压力有些大,需要帮手来帮忙分担任务,于是就演变为下图
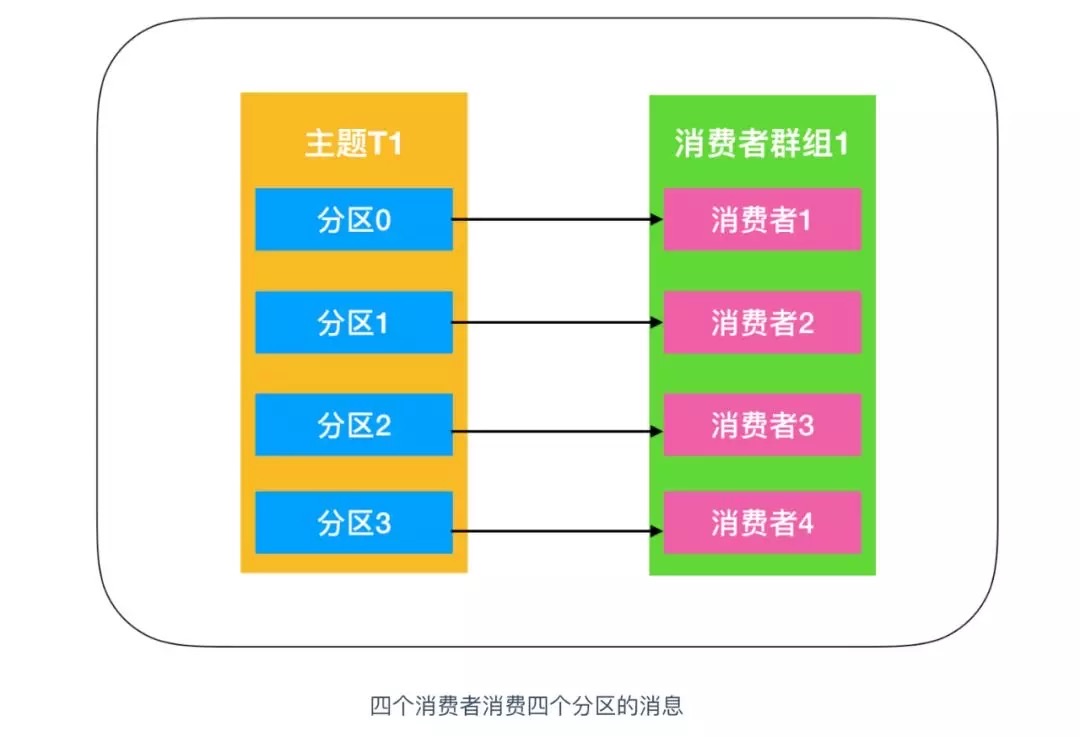
如上图所示,每个分区所产生的消息能够被每个消费者群组中的消费者消费,如果向消费者群组中增加更多的消费者,那么多余的消费者将会闲置,没有任何帮助,因此消费者的数量不应该比分区数多,没有任何帮助,如下图所示
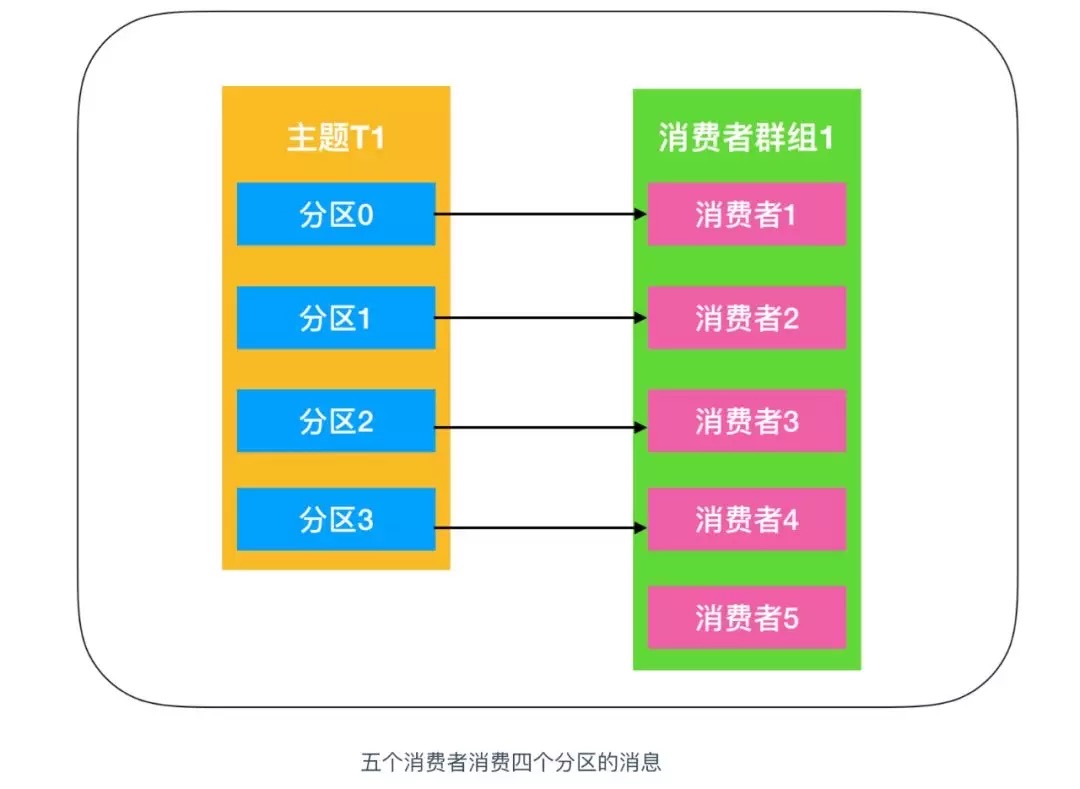
**总结起来就是如果应用需要读取全量消息,那么请为该应用设置一个消费组;如果该应用消费能力不足,那么可以考虑在这个消费组里增加消费者。 **
Properties properties=new Properties();
properties.put("bootstrap.servers","127.0.0.1:9092");
properties.put("group.id","group.id");properties.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");properties.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer=new KafkaConsumer<>(properties);
kafkaConsumer.subscribe(Collections.singletonList("customerTopic"));
我们知道,Kafka 是支持订阅/发布模式的,生产者发送数据给 Kafka Broker,那么消费者是如何知道生产者发送了数据呢?其实生产者产生的数据消费者是不知道的,KafkaConsumer 采用轮询的方式定期去 Kafka Broker 中进行数据的检索,如果有数据就用来消费,如果没有就再继续轮询等待。
ConsumerRecords<String, String> records=kafkaConsumer.poll(Duration.ofSeconds(5));
@Test
public void test(){
Properties properties=new Properties();
properties.put("bootstrap.servers","127.0.0.1:9092");
properties.put("group.id","group.id");
properties.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer=new KafkaConsumer<>(properties);
kafkaConsumer.subscribe(Collections.singleton("pay-callback"));
ConsumerRecords<String, String> records=kafkaConsumer.poll(Duration.ofSeconds(5));
Iterator<ConsumerRecord<String, String>>iterator=records.iterator();
while(iterator.hasNext()){
final ConsumerRecord<String, String> record=iterator.next();
Optional<?> kafkaMessage=Optional.ofNullable(record.value());
if(kafkaMessage.isPresent()){
Object message=kafkaMessage.get();
if(message!=null){
System.out.println("groupId = group.id 消费消息:"+message.toString());
}
}
}
}
2. Kafka 的应用场景
Kafka 可以建立流数据管道,可靠性的在系统或应用之间获取数据。建立流式应用传输和响应数据。
1、作为消息系统 2、作为存储系统 3、作为流处理器
2.1 Kafka 作为消息系统
Kafka 作为消息系统,它有三个基本组件
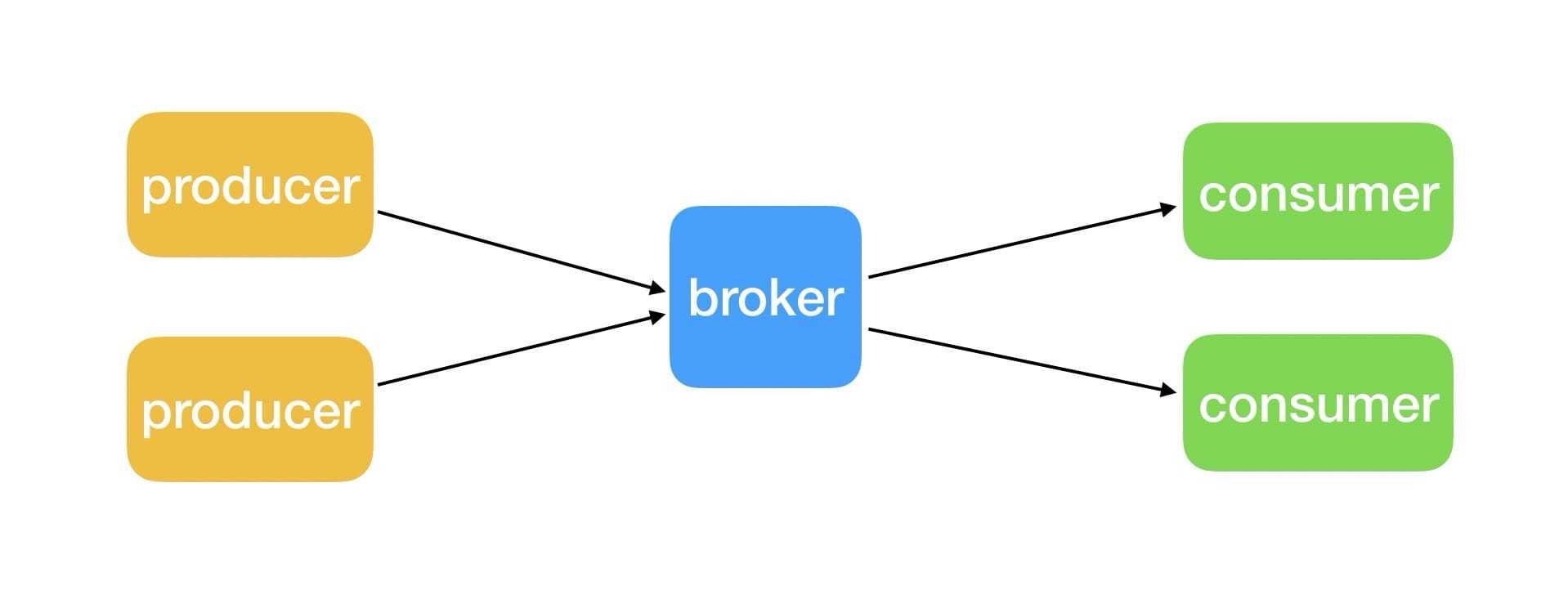
- Producer : 发布消息的客户端
- Broker:一个从生产者接受并存储消息的客户端
- Consumer : 消费者从 Broker 中读取消息
资料: Kafka Producer Kafka Counsumer kafka kafka控制器 kafka副本机制和请求过程 kafka