JAVA 的垃圾回收机制
在 JAVA 的世界里,对不再使用的对象的销毁,不需要我们特别的关注,一切都由 JVM 代替我们处理,以至于很长时间,我根本不了解 JAVA 的垃圾回收机制。但是这不代表垃圾回收不重要,相反当你知道的东西越多后,越能体会它的重要。
什么是垃圾回收?
垃圾回收(GC)就是对释放垃圾占用的内存空间,防止越来越多的垃圾造成的 内存泄露 ;对内存堆中已经死亡的、长期没有被使用的对象进行清理的过程。
什么是垃圾(垃圾的定义)?
喝完饮料的饮料罐是垃圾, 吃完外卖的外卖盒是垃圾,在 JAVA 中也有一些类似 喝完、 吃完的指标表示该对象是否被认为是垃圾,需要被回收。
- 引用计数法
引用计数算法(Reachability Counting)是通过在对象头中分配一个空间来保存该对象被引用的次数(Reference Count)。如果该对象被其它对象引用,则它的引用计数加1,如果删除对该对象的引用,那么它的引用计数就减1,当该对象的引用计数为0时,那么该对象就会被回收。
String m = new String("jack");
先创建一个字符串,这时候"jack"有一个引用,就是 m。
然后将 m 设置为 null,这时候"jack"的引用次数就等于0了,在引用计数算法中,意味着这块内容就需要被回收了。
但是JVM并没有采用这种回收机制,因为引用计数法,会存在由于相互引用导致无法回收的情况。
- 定义2个对象
- 相互引用
- 置空各自的声明引用
- 可达性分析法
可达性分析算法(Reachability Analysis)的基本思路是,通过一些被称为引用链(GC Roots)的对象作为起点,从这些节点开始向下搜索,搜索走过的路径被称为(Reference Chain),当一个对象到 GC Roots 没有任何引用链相连时(即从 GC Roots 节点到该节点不可达),则证明该对象是不可用的。
通过可达性算法,成功解决了引用计数所无法解决的问题-“循环依赖”,只要你无法与 GC Root 建立直接或间接的连接,系统就会判定你为可回收对象。那这样就引申出了另一个问题,哪些属于 GC Root。
GC Root
- 虚拟机栈中引用的对象
- 方法区中常量引用的对象
- 方法区中类静态属性引用的对象
- 本地方法栈中 JNI(即一般说的 Native 方法)引用的对象
- 虚拟机栈中引用的对象
public class GcTest {
public GcTest() {
}
public static void main(String[] args) {
GcTest gcTest = new GcTest();
// 当 gcTest 变量被至空时,其之前所指的对象将被回收。
gcTest = null;
}
}
- 方法区中静态属性引用的对象
public class GcTest {
public static GcTest staticGcTest;
public GcTest() {
}
public static void main(String[] args) {
// GcTest.staticGcTest 指的对象为 GC Root
GcTest.staticGcTest = new GcTest();
}
}
垃圾回收算法
Java 虚拟机规范中并没有明确的指出该如何的实现垃圾回收器,因此,不同的厂商采用不同的方式进行垃圾回收。常见的垃圾回收算法有一下几种。
- 标记-清除算法
- 复制算法
- 标记-整理算法
标记-清除

标记清楚算法分为两个部分:
-
part1:标记,将内存中的对象分为两个部分,可回收、存活
-
part2:清除,将可回收的垃圾,变成未使用的区域。
但是标记-清除算法最大的弊端是内存的碎片化。导致即时有很多内存,但是就是没法使用。因为在申请内存时需要的是连续的空间。比如需要连续的2M的内存空间,但是剩余的是2个分散的1M的空间,就会造成申请不成功。
复制算法

复制算法是在标记清除的算法基础上演化而来的,旨在解决标记清除算法内存碎片化的问题。
该算法将可用的内存空间分为大小相等的两个部分,每次只使用其中的一块,当这块用完的时候,将还存活的对象复制到另一块内存中去,然后将这块内存空间清空一次,以保证内存空间的连续性。
但是复制算法的弊端就是,要浪费掉一半的内存。代价高昂。
标记整理(标记-整理-清除)

标记整理算法标记的过程和标记-清除算法一样,后续并不是直接对可回收对象进行清除,而是将存活的对象全部移动的内存区域的一端,然后将另一端的内存空间清空。这样既解决的内存空间碎片化的问题,又解决的内存空间要浪费一半的问题。
但是该算法也有一个很大的问题,它对内存的变动非常的频繁,需要整理所有存活的对象的内存地址,其效率很差。
分代收集
分代收集算法,是融合上述三种基础的回收算法,针对不同特点的对象,使用不同的回收算法,是一种平衡的做法,既兼顾的垃圾回收的效率,有使得内存资源利用最大化,是垃圾回收的最佳实践。
根据对象存活周期的不同将内存分为几个区域:一般分为两个区域,新生代、老年代。
新生代:每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。
老年代:因为对象存活率高、没有额外空间对它进行分配担保,就必须使用标记-清理或者标记整理算法来进行回收
内存分配策略

Java 堆主要分为2个区域【年轻代】与【老年代】,其中年轻代又分 【Eden 区】和 【Survivor 区】,其中 Survivor 区又分 【From 区】 和 【To 区】。
Eden 区
IBM 公司的专业研究表明,有将近98%的对象是朝生夕死,所以针对这一现状,大多数情况下,对象会在新生代 Eden 区中进行分配,当 Eden 区没有足够空间进行分配时,虚拟机会发起一次 Minor GC,Minor GC 相比 Major GC 更频繁,回收速度也更快。
通过 Minor GC 之后,Eden 会被清空,Eden 区中绝大部分对象会被回收,而那些无需回收的存活对象,将会进到 Survivor 的 From 区(若 From 区不够,则直接进入 Old 区)。
Survivor 区
Survivor 区相当于是 Eden 区和 Old 区的一个缓冲,类似于我们交通灯中的黄灯。Survivor 又分为2个区,一个是 From 区,一个是 To 区。每次执行 Minor GC,会将 Eden 区和 From 存活的对象放到 Survivor 的 To 区(如果 To 区不够,则直接进入 Old 区)。 注意此时的To区的身份变为From区了,From区的身份变为To区。所以在gc的时候To区永远是空的。
为什么需要 Survivor 区?
如果没有 Survivor 区,Eden 区每进行一次 Minor GC,存活的对象就会被送到老年代,老年代很快就会被填满。而有很多对象虽然一次 Minor GC 没有消灭,但其实也并不会蹦跶多久,或许第二次,第三次就需要被清除。这时候移入老年区,很明显不是一个明智的决定。
所以,Survivor 的存在意义就是减少被送到老年代的对象,进而减少 Major GC 的发生。Survivor 的预筛选保证,只有经历16次 Minor GC 还能在新生代中存活的对象,才会被送到老年代。
为什么又将 Survivor区 划分为 From 区 和 To 区?
设置两个 Survivor 区最大的好处就是解决内存碎片化。
我们先假设一下,Survivor 如果只有一个区域会怎样。Minor GC 执行后,Eden 区被清空了,存活的对象放到了 Survivor 区,而之前 Survivor 区中的对象,可能也有一些是需要被清除的。问题来了,这时候我们怎么清除它们?在这种场景下,我们只能标记清除,而我们知道标记清除最大的问题就是内存碎片,在新生代这种经常会消亡的区域,采用标记清除必然会让内存产生严重的碎片化。因为 Survivor 有2个区域,所以每次 Minor GC,会将之前 Eden 区和 From 区中的存活对象复制到 To 区域。第二次 Minor GC 时,From 与 To 职责互换(此时From区就变成To区,To区就变成From区),这时候会将 Eden 区和 To 区中的存活对象再复制到 From 区域,以此反复。
这种机制最大的好处就是,整个过程中,永远有一个 Survivor space 是空的,另一个非空的 Survivor space 是无碎片的。那么,Survivor 为什么不分更多块呢?比方说分成三个、四个、五个?显然,如果 Survivor 区再细分下去,每一块的空间就会比较小,容易导致 Survivor 区满,两块 Survivor 区可能是经过权衡之后的最佳方案。
Old 区
老年代占据 2/3 的堆内存,只有在 Major GC 的时候才会进行清理,每次进行 Major GC 会触动 stop the world,由于Old区,对象的存活率较高,采用标记整理算法。
https://zhuanlan.zhihu.com/p/42747056
https://www.yuhangma.com/2019/java/2019-04-28-object-initialize/
对象创建过程
public class T {
int a = 8;
public static void main(String[] args) {
T t = new T();
}
}
对应的字节码
0 new #3 <T>
3 dup
4 invokespecial #4 <T.<init>>
7 astore_1
8 return
第一条是 new :执行完 new 指令后,在 JVM 堆里申请了一块内存。
第三条invokespecial #4 <T.
第四条 astore_1 :将 new 出来的对象 和 引用 t 进行关联。
刚在申请到内存空间时,是一个半初始化的状态,此时 a 的值是默认值为 0;当调用完构造方法后,才将 a 的值设置为初始值 8;
申请内存 -> 设置初始值 -> 建立关联
对象的分配过程(HotSpot JVM)
在分配对象时,优先在栈上分配,在栈上分配需要满足 逃逸分析 、 标量替换,在时 HotSpot JVM
的优化,在栈上分配对象的好处是,当这个方法调用完成,栈帧就弹出,对象也就销毁了,不会涉及到 GC 对堆中的对象的回收过程。
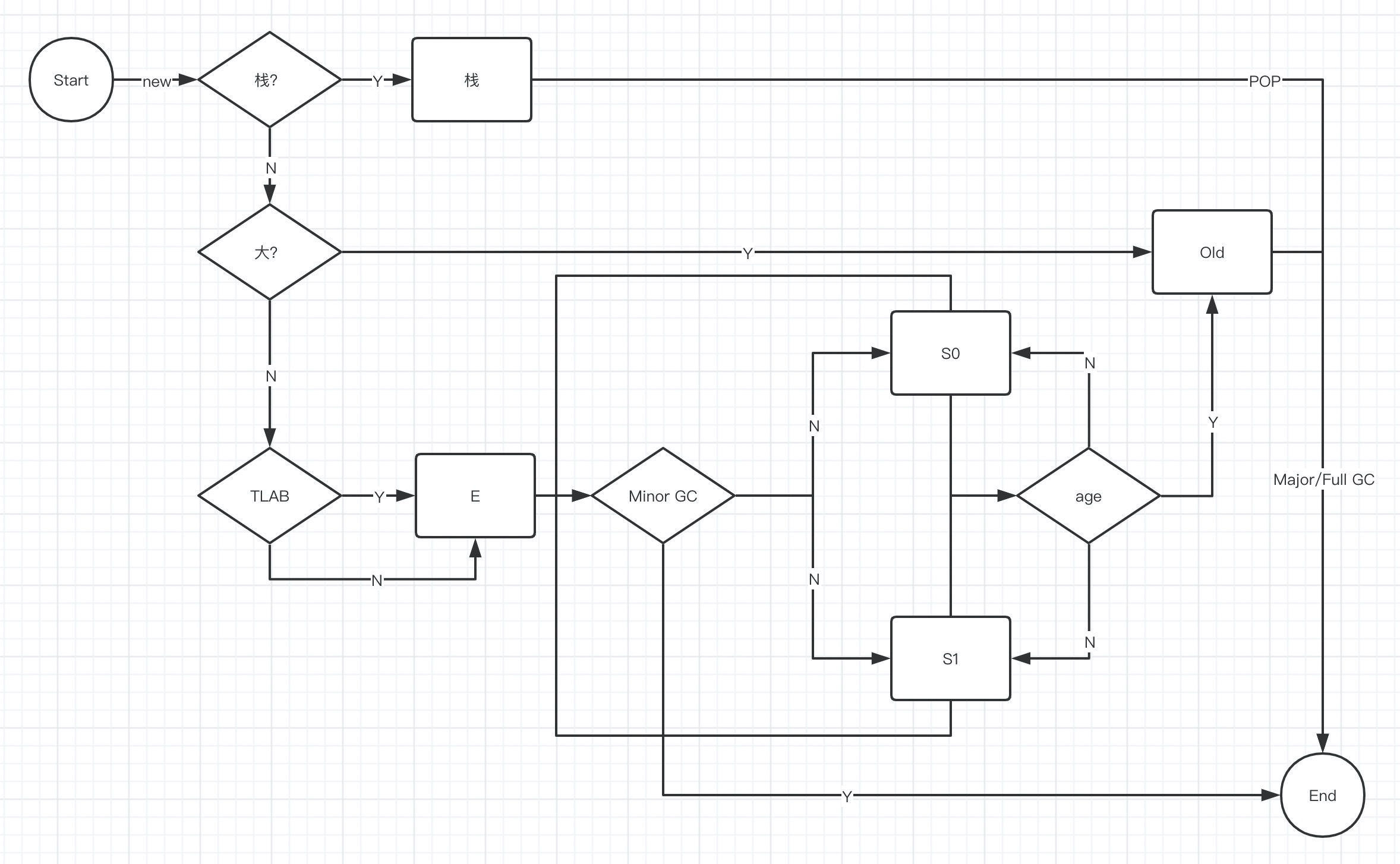
对象过大直接分配到 Old 区,如果不大分配到 Eden 区,看是否开启了 TLAB ,开启了 TLAB 相当于 Eden 区对线程预先分配了一定的内存空间,用来创建对象,在这部分空间创建对象时是不需要竞争锁的,如果不在这部分空间创建需要经历一个自旋锁的过程。
Eden 区对象经过一充 Minor GC 没有被回收的就会进入 Survivor 区,在 Survivor 区的对象经过 Minor GC 后年龄达到一定的数值后会进入 Old区。
在 Old 区的对象会经历 Major GC 或是 Full GC 后被回收。
-XX:-DoEscapeAnalysis //关闭逃逸分析
-XX:-EliminateAllocations //关闭标量替换
-XX:-UseTLAB //关闭 TLAB
对象在内存中的存储布局(HotSpot 64bit)
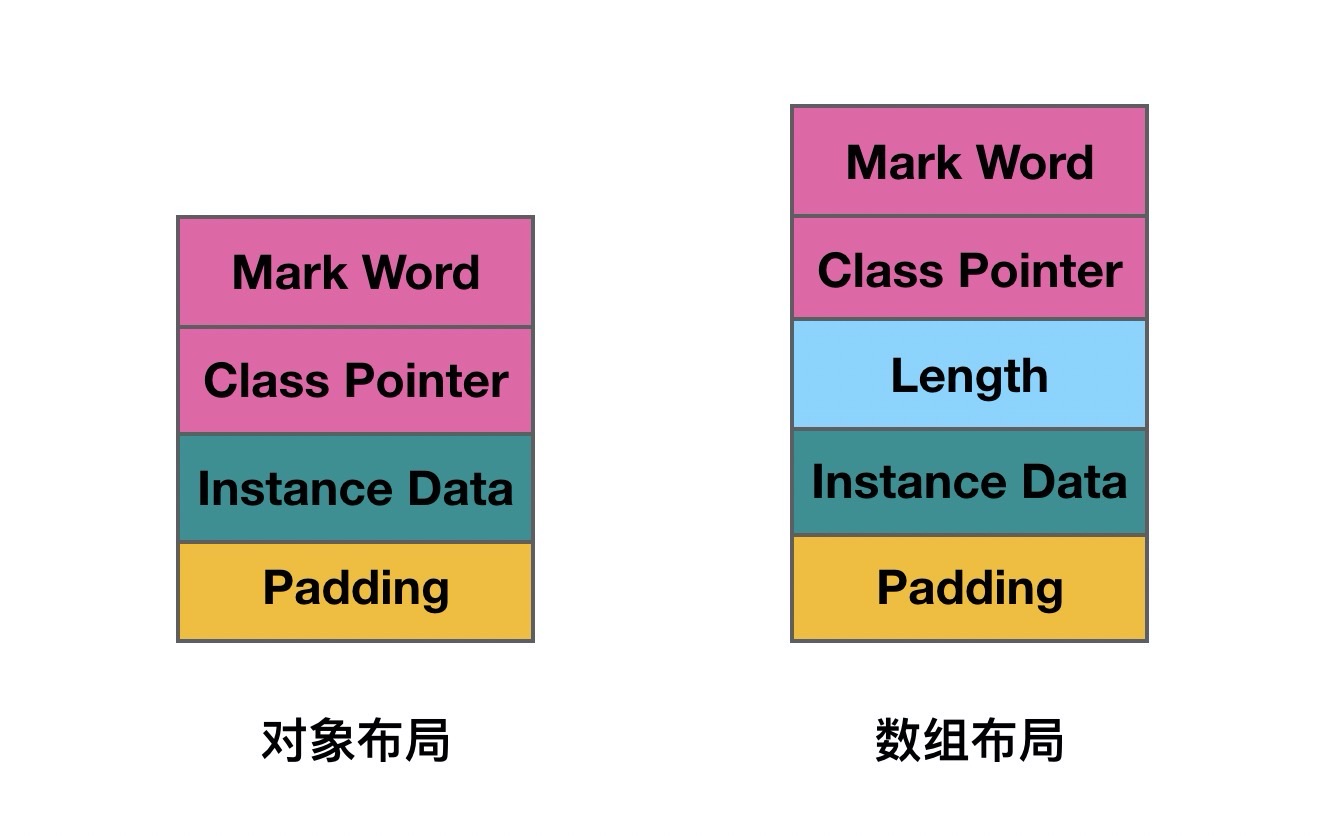
$$ 对象头\begin{cases}Mark Word\Class Pointer\end{cases} $$
Mark Word 占 8byte
Class Pointer 占 4byte / 8byte
Instance Data 是对象中所以属性占的大小之和
Padding 对齐填充,非必须,当 Mark Word + Class Pointer + Instance Data 不能被 8 整除时,通过 Padding 使得对象的大小可以被 8 整除。
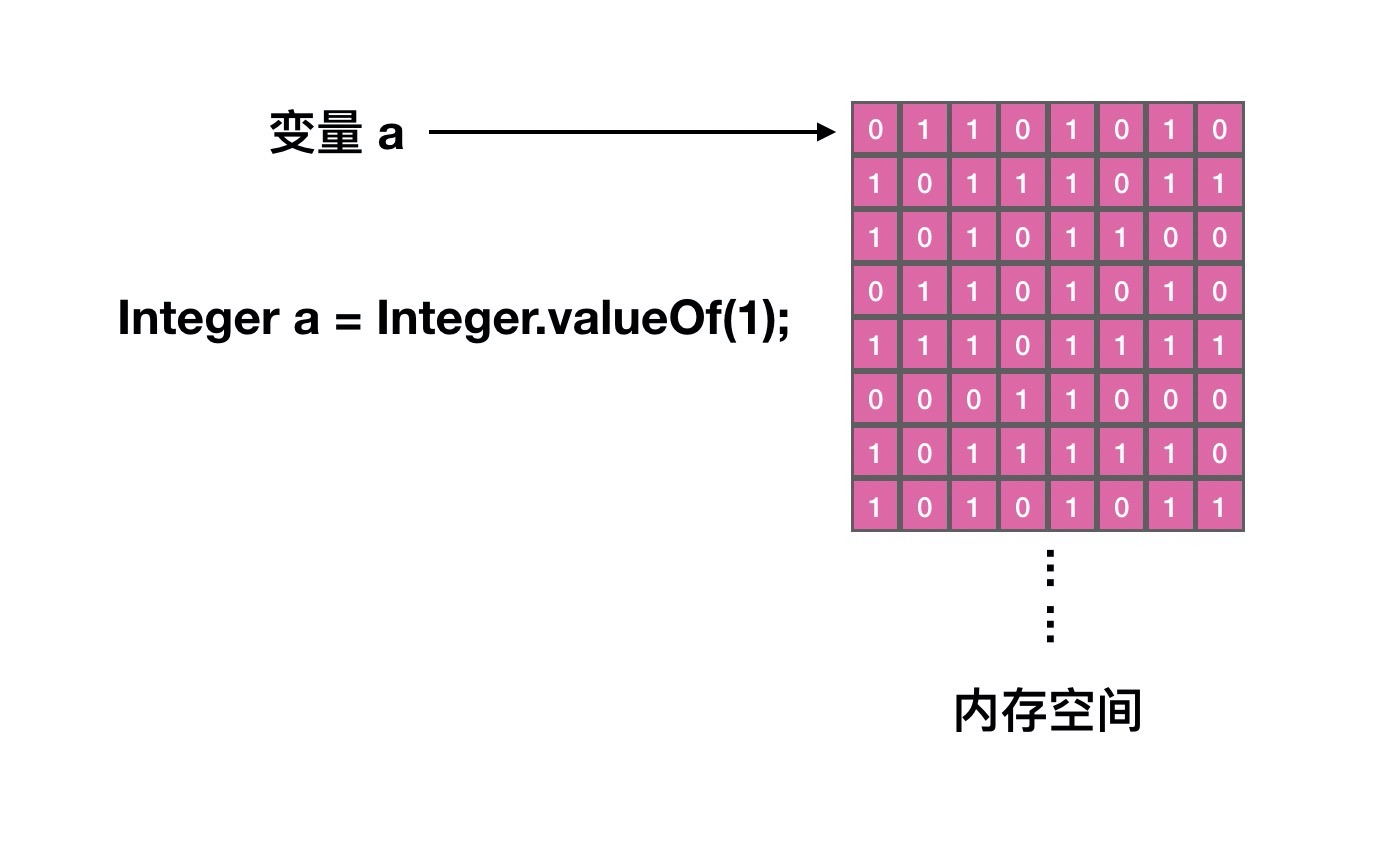
变量 a 存放的是这个 Integer 对象所在堆内存中的起始地址,这个地址的大小占 8byte,Integer 对象本身的大小是 16byte 。至于为什么只需要存放起始地址就可以确定这个对象,是因为已经确定了这个变量 a 的类型是 Integer 类型,其所占的空间大小也就是确定的,进而也就确定了在内存中从起始地址到结束地址的偏移量。
如果 JVM 开启了 oops,那么变量 a 所占的大小就是 4byte,默认是开启了 oops 的,可以通过 -XX:-UseCompressedOops 禁用 oops 。
则 UseCompressedOops 会使用 32-bit 的 offset 来代表 Java Object 的引用,而``UseCompressedClassPointers` 则使用 32-bit 的
offset 来代表 64-bit 进程中的 ClassPointer;
4byte 32bit 的 ClassPointer 的最大寻址空间是 4GB
对象头包含什么
如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等
在32位系统占 4 字节,在 64 位系统中占 8 字节

synchronized 是锁对象,而不是锁代码,锁升级过程 偏向锁 -> 自旋锁 -> 重量级锁
偏向锁:偏向于某个线程的锁。
自旋锁:当有多个线程竞争这把锁的时候,升级为自旋锁 (cas)
bit 意为“位”或“比特”,是电子计算机中最小的数据单位,是计算机存储设备的最小单位,每一位的状态只能是0或1。
byte 意为“字节”,8 个二进制位构成1 个 byte,即1byte = 8bit,两者换算是 1:8 的关系,字节是计算机处理数据的基本单位,即以字节为单位解释信息。1 个字节可以储存 1 个英文字母或者半个汉字,换句话说,1个汉字占据2个字节的存储空间。
评判 GC 的3个核心指标:
-
内存占用(Footprint)
-
延迟(Latency):也可以理解为最大停顿时间,即垃圾收集过程中一次 STW 的最长时间,越短越好,一定程度上可以接受频次的增大,GC 技术的主要发展方向。
-
吞吐量(Throughput):应用系统的生命周期内,由于 GC 线程会占用 Mutator 当前可用的 CPU 时钟周期,吞吐量即为 Mutator 有效花费的时间占系统总运行时间的百分比,例如系统运行了 100 min, GC 耗时1min,则系统吞吐量为 99%,吞吐量优先的收集器可以接受较长的停顿。 目前各大互联网公司的系统基本都更追求低延时,避免一次 GC 停顿的时间过长对用户体验造成损失, 衡量指标需要结合一下应用服务的 SLA,主要如下两点来判断: